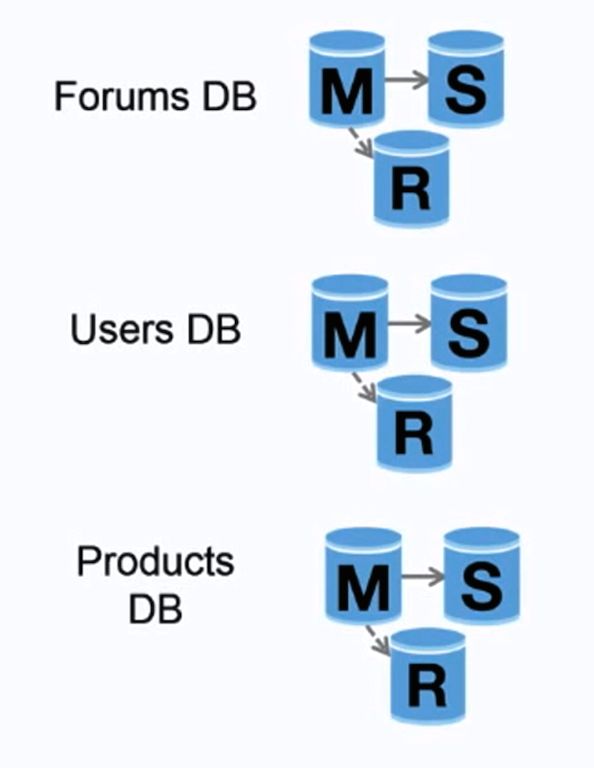
It is a method of splitting databases by function or domain. Instead of having a single database for all your data, you create a separate database for each domain, which would result in less read and write traffic for each db and less replication lag.
Also, smaller databases can store more information in memory, which results in more cache hits due to improved cache locality. And lastly, because your writes are distributed, you can write simultaneously to multiple databases which improves throughput.
Disadvantages
- Not effective if your schema requires huge tables
- Your application logic will require updating so it knows to which database it should talk to
- Joining data from databases will have to happen on an application layer rather than database layer
- More hardware and additional complexity