
Summary
What is Domain Driven Design
- Tool to analyse business domains and strategy of the business
- helps with shared understanding of the business between stakeholders
- drives high level decisions thanks to the shared understanding of the business which helps with decomposition of systems into components and definition of integration patterns.
- It helps to align technical team with non-technical teams and to speak the same language
Business Domain
- a service that company provides to its customers
- example: a courier delivery delivering parcels, serving coffee or food
- Businesses may have multiple business domains
- example of multiple business domains: Amazon with ecommerce but also cloud infrastructure.
- Business domain as at the core of DDD
Subdomain
- More details sub category of business domain, more fine-grained area of business activity
- One subdomain is not enough to help the business reach the goal, all of them have to be combined together
- Subdomains have to interact with each to help the business fulfil its mission. They are all required
- They can be technical and non-technical
- Subdomains help you to focus on things that give you competitive advantage and avoid implementing features that can be outsourced.
Types of Subdomains
Core Subdomain
- It is what the company does differently from its competitors
- it can be an innovative product but also a way of reducing the cost or optimising the processes that already exist
- are complex by nature and should be hard to implement, but also hard to copy by competitors. Otherwise, it is short-lived.
- Because core subdomain is novel, it should always evolve, should always be refined. That means, core domains can be volatile
- Most probably should be implemented in-house
Generic Subdomain
- business activities that all businesses perform the same way
- do not provide any competitive advantage
- Complex and hard to implement, just like a core subdomain, but they do not provide competitive edge for the company
- Can be bought or adopted. It’s already solved, so business shouldn’t focus on it
- Example: Authentication and Authorisation
Support Subdomain
- support company’s business
- do not provide competitive advantage
- Simple
- It usually resembles typical CRUD
- They can be implemented in-house if a solution doesn’t exists yet, but can be outsourced.
- Example: Web app
How to identify Differentiate Core from Supporting subdomain
- It should be something that you can turn into a side business or it should be something someone would pay for its own
How to Identify Subdomains
- Subdomains are usually already in a bustiness strategy, they just need to be discovered
- A good starting point is company’s departments and organisational units and start defining
Domain Expert
- expert in a certain part of the business. Someone that can always be reached out to gain knowledge from to help to model and implement the software
- Domain experts do not have to be technical. They are the representatives of the business
- They identified the business problem
- As a rule of thumb, they are people that come up with requirements or end users of the software, because software has to solve a problem of domain expert
Software has to mimic the mental model of a domain
Software has to represent how people think about the domain and how it works. Without understanding what the business problem is, the requirements and solutions won’t
Domain knowledge shouldn’t be translated
- Translation of domain knowledge into engineer friendly form is not great
- translation is hazardous to knowledge sharing as people will use different terms between tech and non-tech teams
- when translating the domain knowledge, that is essential for solving problems is lost on the way to engineers, because it is distorted
- translation of domain knowledge is one of the main causes of failed software projects.
What is Ubiquitous Language
- Language used by developers and business people, as well as domain experts to communicate efficiently
- Language of the business, because of that, it should consist of business domain-related terms
- It is not ubiquitously applied throughout the organisation. It is applied within its bounded context
Main points of Ubiquitous Language
- It must be consistent and precise; there should be no room left for assumptions and business domain logic should be explicit
- Terms should have only one meaning to avoid ambiguity; that means, if different teams use the same word, but in their business domain have a different meaning, they need to be made more precise
- Ubiquitous language is not used ubiquitously across the organisation. It used within its bounded context
Documentation of Ubiquitous language is crucial for effective communication
- Every business domain should have a glossary with ubiquitous language
- Glossary should be updated when something changes
- glossary should be updated by all team members
What is a Domain Business Model
- a simplified version of a real wold problem, something that helps to make sense of a system.
- effective models only have details that are needed to fulfil its purpose
- models should not be a copy of a real world, it should only contain enough information to solve a problem
- The purpose of it is to capture domain expert’s mental model, their through process about how it works
Why Modelling of a business domain is important
- it helps to discover knowledge that is already there
- you may discover ambiguities or white spots in the understanding of the business domain, as they mainly cover the
happy pathscenarios, but don’t consider edge cases - The above may help with discover business domain concepts that lack of definition
Bounded Context
- Strategic design decision that helps to divide the business domain into smaller, manageable problem domains
- Helps with a definition of physical and ownership boundaries
- Division of ubiquitous language into smaller ones where words from ubiquitous language have assigned meaning
- It helps with resolving conflicts within business domain where the definition of a thing changes
- Bounded contexts have to integrate with one another
Types of Boundaries
Physical
- A boundary that helps with implementation of systems independently (physically separate)
- Each service or project should be implemented, evolved, and versioned independently of other boundaries.
Ownership
- A boundary that helps with division of work between teams, and assign team to take an ownership over a particular boundary
- A bounded context should be implemented and maintained by one team, and no more teams can work on the same bounded context
- helps with elimination of implicit assumptions about another’s model, and forces teams to define communication protocols for integrating models with system explicitly
- relationship between teams and boundaries is one-directional; one bounded context can be owned by one team, but one team can own multiple bounded contexts
Contracts
It is a touchpoint between systems. They help both systems to communicate together without having to create dependencies.
Contract Patterns
Cooperation
- Implemented by teams with well-established communication; implemented by a single team
- success of one team depends on a success of another team
- the main criterion is the quality of the teams’ communication and collaboration
Partnership Model
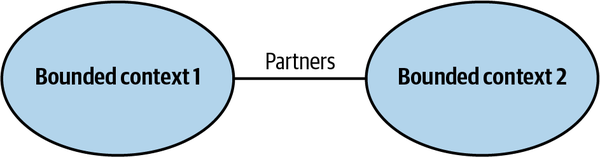
- integration between both is implemented ad-hoc
- one team can notify about the change and second team will adapt and cooperate
- coordination of integration is bidirectional; no one team dictates the language for contracts
- both teams cooperate in solving integration issues that may come up
- neither of a team is interested in blocking one another
- collaboration practices, high levels of commitment and frequent synchronisation between teams are required for this pattern to work
- this pattern is not a good fit for geographically distributed teams due to synchronisation and communication challenges
Shared Kernel
- a subdomain or part of it is implemented in multiple bounded contexts
- a shared model has to be consistent across all bounded contexts that are using it
- implemented by multiple teams
- Implementation
- if monorepos are used use the same source files referenced by multiple bounded contexts
- a package can be created that exposes a contract that can be used by other bounded contexts
- every change will have to trigger an integration tests for all bounded contexts
- When to use it
- because this pattern introduces a strong dependency between bounded contexts, it should be implemented when the cost of duplication is higher than the cost of coordination
- gradual modernisation of a legacy system, but this should only be as a temporary solution
- When a team works closely together, but wants to have a way to test that the change they make does not affect the other team (Similar to Partnership model, but coordinated)
Customer - Supplier
- upstream or downstream team can dictate the integration contract
Conformist
- It is a take it or leave it model
- A consumer has to adjust how it is going to adjust to the contract, because upstream team have little motivation to support clients’ needs
- This is usually the case when you have to integrate an external service or use something that external organisation provides (hence why it’s called conformist)
- It usually happens, when the service that the organisation provides is an industry standard and is well established.
Anticorruption layer
- the power to dictate the contract is towards the upstream
- the downstream bounded context translates the upstream bounded context’s model into a model that it needs for its needs
- Usually used when there is no desire or its worth an effort to conform to the supplier’s model
- When the downstream bounded context has a core subdomain
- Upstream model is inconvinente for the consumer’s needs
- When contract of the supplier changes often
Open host service
- Power is skewed towards the consumer
- Supplier has to adjust and provide the best service possible
- To protect customers, provider decouples the implementation model from the public interface
-
Allows supplier to evolve implementation and public models at different rates
-
Separate Ways
- used when communication is difficult due to organisation’s size or politics. Teams that have hard time collaborating or agreeing on things. In those cases it may be better to have a bit of duplication.
- Should be avoided if you are integrating core subdomains
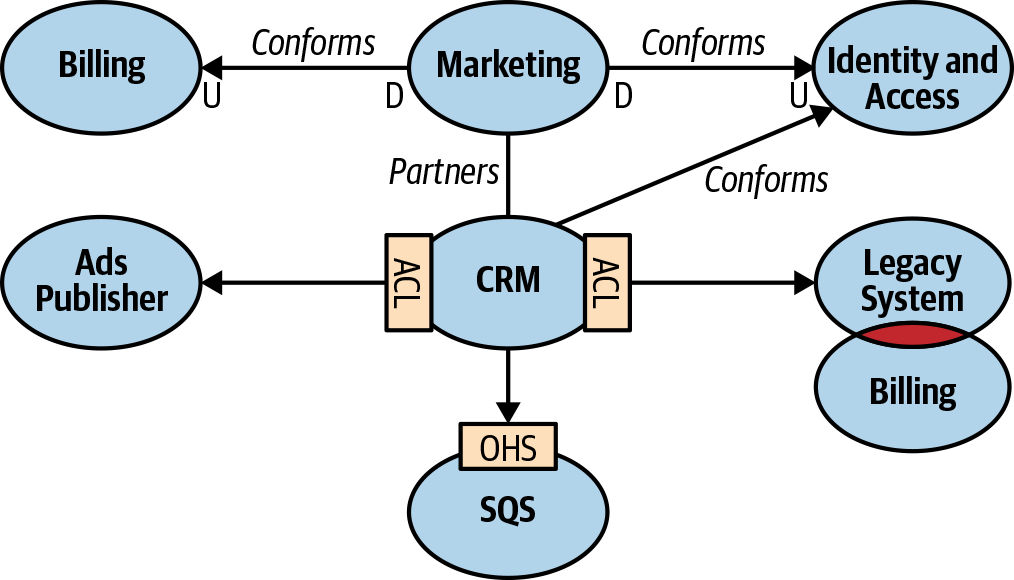
Context Maptodo
- A visual representation of the system’s bounded contexts and integration between them
- A step taken after creating contracts between systems
Benefits of having a context map
- High Level Design: gives you an overview of the system’s components and models they implement
- Comms patterns: Shows you the communication patterns between teams
- Organisation Issues: Can give you an insight into issues with organisation. For example, if all of them use separate ways or anticorruption pattern.
Open: Pasted image 20240814204345.png
Tactical Design
Domain model
- a model of a domain that incorporates behaviour and data.
- value objects, domain events, aggregates and domain services are the building blocks of that model
- all the patterns above put the business logic first
- should be devoided of any infra or tech concerns like calls to database or other external components of the system
- domain objects should be implementing business logic without relying on or directly incorporating infra components or frameworks
- because it implement complex business logic, it is safe to assume that this usually will be used with core subdomains
Building Blocks
Value Objects
- immutable type defined by its properties rather than a unique identity
- they are distinguished by attributes
- Characteristics
- Immutable: once created, their value doesn’t change
- Equality: value objects are compared based on attributes
- Self-validation: they ensure that the validity is within them when created
- No Identity: they do not have any identity
class Money {
private readonly amount: number;
private readonly currency: string;
constructor(amount: number, currency: string) {
if (amount < 0) {
throw new Error('Amount cannot be negative');
}
if (currency.length !== 3) {
throw new Error('Currency must be a 3-letter ISO code');
}
this.amount = amount;
this.currency = currency.toUpperCase();
}
public getAmount(): number {
return this.amount;
}
public getCurrency(): string {
return this.currency;
}
public equals(other: Money): boolean {
return this.amount === other.amount && this.currency === other.currency;
}
public add(other: Money): Money {
if (this.currency !== other.currency) {
throw new Error('Cannot add different currencies');
}
return new Money(this.amount + other.amount, this.currency);
}
public toString(): string {
return `${this.amount.toFixed(2)} ${this.currency}`;
}
} - they centralise the business logic for values manipulation which makes it easier to test
- they express the business domain and speak the ubiquitous language
- when making changes to a value, you have to create a new one as conceptually, they are immutable
- You should use value objects wherever you can
- it makes code safer and encapsulates the business logic
Entity
- The opposite of the value object (it requires an id to distinguish different instance of the entity)
- An example of an entity could be a person object that takes value objects as types and uses value objects
- ids in entities have to be unique for each instance of the entity (for example for each product)
- id should remain immutable through the entity’s lifecycle
- they are mutable and it is expected to change
class Money {
private readonly amount: number;
private readonly currency: string;
constructor(amount: number, currency: string) {
if (amount < 0) {
throw new Error('Amount cannot be negative');
}
if (currency.length !== 3) {
throw new Error('Currency must be a 3-letter ISO code');
}
this.amount = amount;
this.currency = currency.toUpperCase();
}
public getAmount(): number {
return this.amount;
}
public getCurrency(): string {
return this.currency;
}
public equals(other: Money): boolean {
return this.amount === other.amount && this.currency === other.currency;
}
public toString(): string {
return `${this.amount.toFixed(2)} ${this.currency}`;
}
}
class ProductId {
private readonly value: string;
constructor(value: string) {
if (!value.match(/^PROD-\d{6}$/)) {
throw new Error('Invalid product ID format. Must be PROD-XXXXXX where X is a digit.');
}
this.value = value;
}
public getValue(): string {
return this.value;
}
public equals(other: ProductId): boolean {
return this.value === other.value;
}
public toString(): string {
return this.value;
}
}
class Product {
private readonly id: ProductId;
private name: string;
private price: Money;
private stockQuantity: number;
constructor(id: ProductId, name: string, price: Money, stockQuantity: number) {
this.id = id;
this.name = name;
this.price = price;
this.stockQuantity = stockQuantity;
}
public getId(): ProductId {
return this.id;
}
public getName(): string {
return this.name;
}
public setName(name: string): void {
this.name = name;
}
public getPrice(): Money {
return this.price;
}
public setPrice(price: Money): void {
this.price = price;
}
public getStockQuantity(): number {
return this.stockQuantity;
}
public addStock(quantity: number): void {
if (quantity < 0) {
throw new Error('Quantity to add must be positive');
}
this.stockQuantity += quantity;
}
public removeStock(quantity: number): void {
if (quantity < 0) {
throw new Error('Quantity to remove must be positive');
}
if (this.stockQuantity < quantity) {
throw new Error('Not enough stock');
}
this.stockQuantity -= quantity;
}
public equals(other: Product): boolean {
return this.id.equals(other.id);
}
}
// Creating a product
const productId = new ProductId('PROD-123456');
const productPrice = new Money(29.99, 'USD');
const product = new Product(productId, 'Fancy Gadget', productPrice, 100);
// Using the product
console.log(product.getName()); // Output: Fancy Gadget
console.log(product.getPrice().toString()); // Output: 29.99 USD
console.log(product.getStockQuantity()); // Output: 100
// Modifying the product
product.setName('Super Fancy Gadget');
product.setPrice(new Money(39.99, 'USD'));
product.removeStock(10);
console.log(product.getName()); // Output: Super Fancy Gadget
console.log(product.getPrice().toString()); // Output: 39.99 USD
console.log(product.getStockQuantity()); // Output: 90 Aggregate
- It is like entity
- requires id field and is mutable
- its goal is to protect the consistency of data
- it is a consistency enforcement boundary
- it validates all incoming modifications and ensure that changes do not contract its business rules
- only aggregates business logic can modify its state, external processes can only read the state
- its state can be only mutated executing methods that are exposed publicly
- public interface of an aggregate is responsible for validation and enforcing all business relevant rules and invariants
- this helps with business logic being implemented in the aggregate
- public interface has to load the current state, execute action, persist the modified state and return operation’s result to the caller
- consistency of aggregates state has to be protected in a case where multiple processes are concurrently updating the same aggregate
- in such case, 2nd process has to be notified that the state on which it had based its decision is out of date and has to retry
- contains value objects and entities
- if information can be eventually consistent, it should reside outside of aggregate
- aggregates should be small, include only objects that are required to be in consistent state.
- aggregates, when communicating with each other, should use ids
// Value Object: Money
class Money {
constructor(private amount: number, private currency: string) {}
add(other: Money): Money {
if (this.currency !== other.currency) {
throw new Error("Cannot add different currencies");
}
return new Money(this.amount + other.amount, this.currency);
}
toString(): string {
return `${this.amount} ${this.currency}`;
}
}
// Value Object: Address
class Address {
constructor(
private street: string,
private city: string,
private zipCode: string,
private country: string
) {}
toString(): string {
return `${this.street}, ${this.city}, ${this.zipCode}, ${this.country}`;
}
}
// Entity: OrderItem
class OrderItem {
constructor(
private id: string,
private productName: string,
private quantity: number,
private unitPrice: Money
) {}
getTotalPrice(): Money {
return new Money(
this.unitPrice.toString().split(' ')[0] as unknown as number * this.quantity,
this.unitPrice.toString().split(' ')[1]
);
}
}
// Aggregate Root: Order
class Order {
private items: OrderItem[] = [];
constructor(
private id: string,
private customerId: string,
private shippingAddress: Address,
private orderDate: Date
) {}
addItem(item: OrderItem): void {
this.items.push(item);
}
removeItem(itemId: string): void {
this.items = this.items.filter(item => item.id !== itemId);
}
getTotalAmount(): Money {
return this.items.reduce(
(total, item) => total.add(item.getTotalPrice()),
new Money(0, "USD")
);
}
// Other methods like changeShippingAddress, cancelOrder, etc.
}
// Usage example
const order = new Order(
"ORD-001",
"CUST-001",
new Address("123 Main St", "New York", "10001", "USA"),
new Date()
);
order.addItem(new OrderItem("ITEM-001", "Product A", 2, new Money(10, "USD")));
order.addItem(new OrderItem("ITEM-002", "Product B", 1, new Money(15, "USD")));
console.log(order.getTotalAmount().toString()); // Output: 35 USD Transaction boundary
- It is an aggregate but it kind of is different.
- the goal of transaction boundary is to make sure that either all changes are committed or none at all
- because of that, all changes should be done as one operation
Domain Event
- describes an event that has occurred in the business domain
- e.g. Ticket assigned, ticket escalated, message received etc.
- because they describe something that has already happened, they need to be described in past tense
- the goal is to describe what happened in the business domain and provide necessary data related to the event
- domain event si part of aggregate public interface and publishes domain events and other aggregates or external systems can subscribe to it and execute their own logic in response to the event
- part of aggregates
Domain Service
- stateless object that implements a business logic
- implemented when the logic doesn’t belong to aggregate or value object
- it usually i used for orchestrating calls to various components of the system to perform some calculation or analysis
- It usually requires information from multiple sources
- it is just a stateless object used for hosting business logic, it should not have its own database or state
Event Sourcing 03-09-2024
- Adds dimension of time into the data model
- that means, every change in an aggregate’s lifecycle is documented
- all domain events use commands to make changes and then aggregate does necessary validation to update or create entity
- The database that stores system’s events is the only consistent storage and that means it is the only source of truth.
- The database used for persisting events is event store
Event sourcing operations
- loads the aggregate’s domain events
- reconstituate a state representation; project the events into a state representatiojn that can be used to make business decisions
- execute aggregate’s command to execute the business logic
- produce new domain event
- commit the new domain event to event store
Advantages
- it allows you to restore all past states of the aggregate as well as current state
- it provides a flexible model that allows for transforming the event into different state representation(?)
- it provides with a strongly consistent audit log of everything that happened to the aggregate’s state
- optimistic concurrency management; it raises an exception when data becomes stale
- stale means it is being overwritten by another process while it is being written
Disadvantages
- Sharp learning curve as it requires changing the way you think about managing data. Team may need training and time to get used to it
- Adds architectural complexity due to numerous moving parts
- It is not easy to evolve event sourced model and make amendments (by definition, events are immutable)
- Resource heavy
- when you start having loads of events, it will get slower or it will require more resource. This can be fixed by caching and snapshots
Event store
- it is a database that persist all data and changes that have happened in the past
- It is append-only storage; nothing should be deleted or changed
- to support event sourcing pattern, event store has to be able to fetch events belonging to the business entity and append events
- when the state is stale and events were added after expected version, event store should raise concurrency exception
- Commonly used in financial industry to represent changes in a ledger
Ledger
- append-only log for documenting all transactions that happened for a particular user
- it helps with representing the current account balance of a customer
- deduction of the money happens by projecting the ledger’s records
Snapshot
- it allows you to reduce time spent on reading events from event store
- it creates a snapshot of an aggregate state
- a typical flow
- command is received
- latest snapshot of an aggregate is read from snapshot store
- if snapshot found, aggregate is set from the snapshot, the aggregate version is set to the snapshot version
- remaining events are read from event store starting from the aggregate version
- state is updated with remaining events
- command is handled as usual
- needs to be justified
- if aggregates do not persist 10000+ events, it doesn’t make sense to add it, because it adds complexity
Deleting datatodo
- sometimes, you may have to delete data from your system, but with DDD and event sourcing, you shouldn’t delete your data
- sensitive data is usually encripted
- you should use an encryption key stored in an external key:value storage where id is the aggregate’s ID and the value is the encryption key
- when sensitive data needs to be deleted, the encryption key is deleted from the key storage
- that makes the data no longer accessible
Architectural Patterns
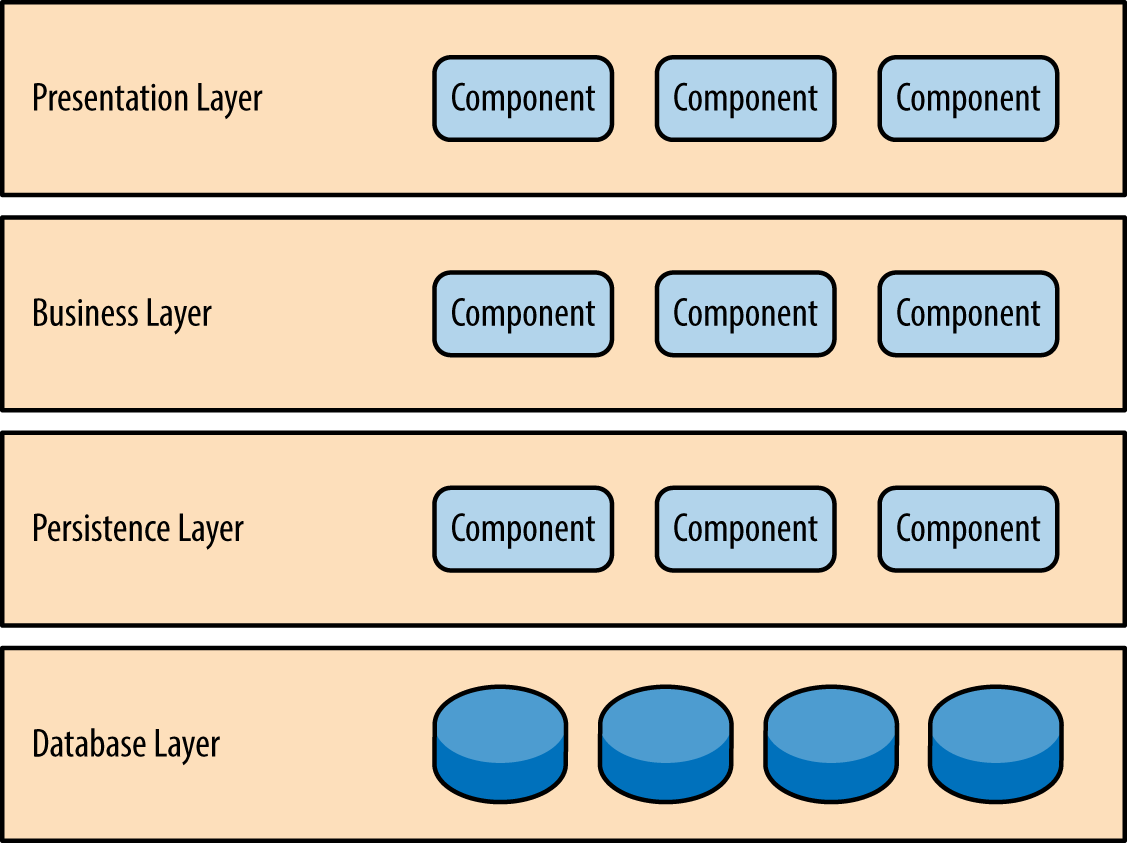
Layered Architecture
- Organises codebase into horizontal layers and each layer addresses one of the following concerns
- interaction with the consumers
- implementing business logic
- persisting the data
- The most commonly used in engineering and most if not everyone understand it
- There are usually 4 layers
- presentation layer
- responsible for handling UI and browser communication
- business layer
- responsible for executing business rules associated with the request
- persistence layer
- database layer
- presentation layer
- Each layer has a specific role and responsibility within the app around the works that needs to be done to satisfy a particular business request
- for example, presentational layer shouldn’t worry about business logic while business logic shouldn’t care about how data is displayed. It should only get the data from persistence layer, perform business logic against it and provide it to the presentational layer.
- (add this)https://www.oreilly.com/api/v2/epubs/9781491971437/files/assets/sapr_0101.png
- it promotes a separation of concerns as every component only cares about it’s bit.
- concepts
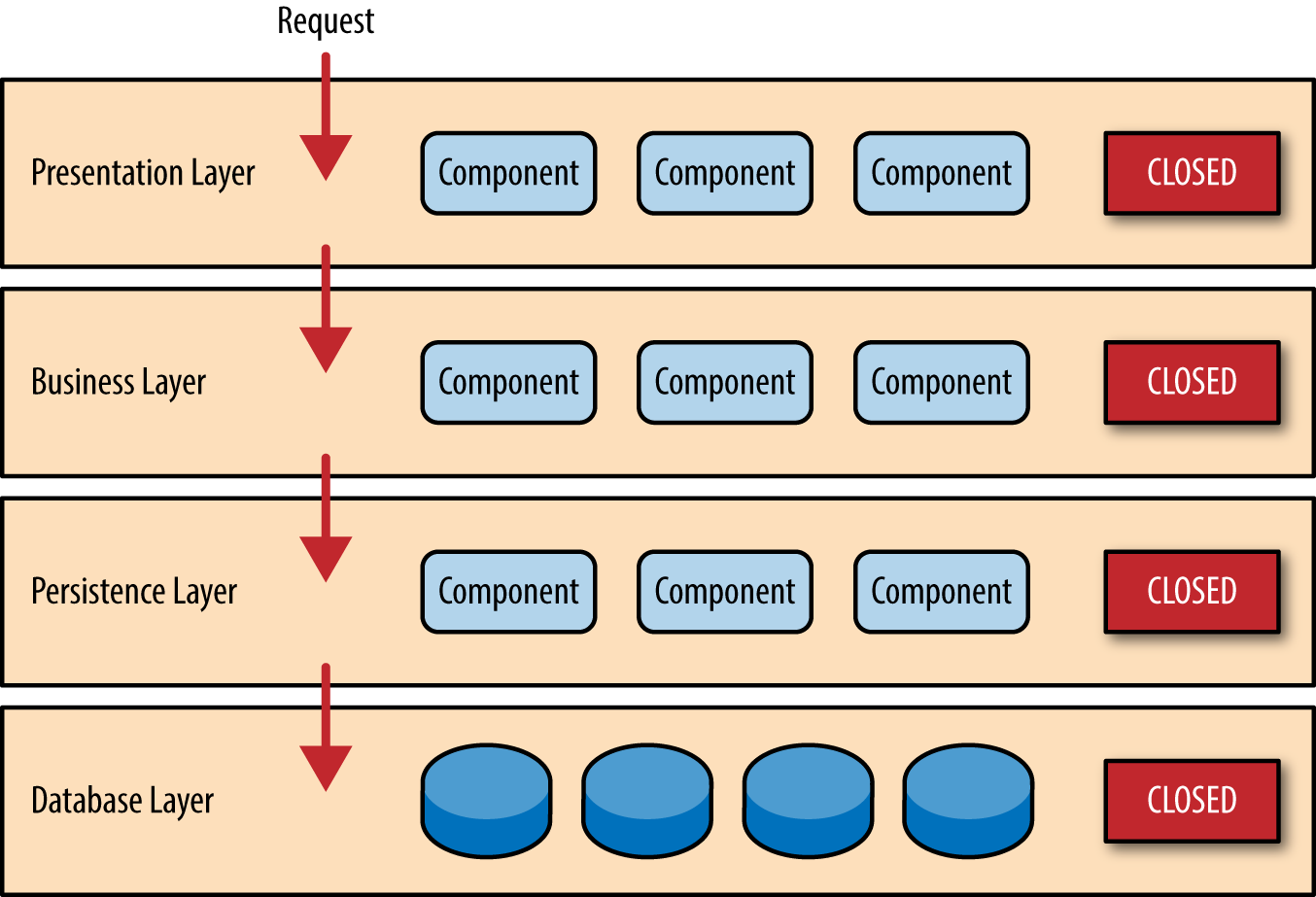
- layers in architecture are closed
- this means that requests has to move form layer to layer and it must go from or to the layer above it or below it and it cannot skip any of those
- https://www.oreilly.com/api/v2/epubs/9781491971437/files/assets/sapr_0102.png
- Pros
- Easy of development - most people are familiar with it
- Cons
- Scalability - doesn’t scale very well in large organisations, especially when lots of changes are required
- Easy of deployment - It is hard to deploy, because deployments have to be coordinated
- Agility - it doesn’t work in environment where you have to constantly change things. If a change is made in one layer, other layers have to be updated due to tight coupling
{kind=link}
{kind=link}
Layers of Isolation
- it is a concept where changes in one layer of the architecture don’t impact or affect components in other layers, because that creates tightly coupling and makes everything very hard and expensive to change
Ports & Adapters
- It aims to decouple an app from the details such as
- web framework
- database choice
- ORM
- third party APIs
- Application Layer Protocol that is used for communication
- Port is a contract that the application uses for communication
- adapter is an abstraction that allows you to add a database or some other API to your application. It converts contract into desired technoloy
- Communication between hexagons (isolated domains) is done via HTTP
- Pros
- Everything is isolated
- Easy to swap services
- Cons
- It adds complexity to your code
- because it uses HTTP for communication, performance may suffer due to latency
CQRS
- query responsibility segregation pattern
- similar to ports and adapters but differs in the way the system’s data is managed
- It allows to represent system’s data in multiple persistent models
- it was initially defined to address limitation of event source model where it is only possible query events of one aggregate instance at the time
- Command is a write model
- Query is a read model
- Implementation
- Command Execution Model
- It is used to implement business logic, validate rules and enforce invariants
- the only model representing strongly consistent data (source of truth)
- command should always let the caller know whether they succeeded or failed, and it should provide an information why did it fail, and if it is caller’s fault, it should let it know how to fix the command.
- Read Models
- precached projection that lives in a database, flat file or in-memory cache
- Projection of Read Models
- whenever source tables are updated, changes have to be reflected in the precached views
- it uses catch up subscription model for it
- There has to be a projection model that is responsible for regenerating and updating system’s read models
- When updating, projection engine uses last processed record to add or modify records
- Async Projections
- Challenges
- Can be crumblesome to use with distributed computing. When messages are processed out of order or duplicated, projections will have incosistent data
- it is better to implement synchronious and optionally add async on top
- Challenges
- Model Segregation
- responsibilities of the system’s models are segregated according to their type; command can only operate on strongly consistent command execution model
- When to use it
- supports DDD core value of working with the most effective models for the task at hand
- With event sourced domain models
- In general, when different technologies need to be used for different purpose.
- Command Execution Model
Highlights
-
According to studies, approximately 70% of software projects are not delivered on time, on budget, or according to the client’s requirements. In other words, the vast majority of software projects fail. This issue is so deep and widespread that we even have a term for it: software crisis. (Location 490)
-
The strategic tools of DDD are used to analyze business domains and strategy, and to foster a shared understanding of the business between the different stakeholders. We will also use this knowledge of the business domain to drive high-level design decisions: decomposing systems into components and defining their integration patterns. (Location 505)
-
DDD’s tactical patterns allow us to write code in a way that reflects the business domain, addresses its goals, and speaks the language of the business. (Location 508)
-
The strategic aspect of DDD deals with answering the questions of “what?” and “why?”—what software we are building and why we are building it. The tactical part is all about the “how”—how each component is implemented. (Location 531)
-
business domain defines a company’s main area of activity. Generally speaking, it’s the service the company provides to its clients. For example: FedEx provides courier delivery. Starbucks is best known for its coffee. Walmart is one of the most widely recognized retail establishments. (Location 564)
-
A company can operate in multiple business domains. For example, Amazon provides both retail and cloud computing services. (Location 568)
-
A subdomain is a fine-grained area of business activity. All of a company’s subdomains form its business domain: the service it provides to its customers. Implementing a single subdomain is not enough for a company to succeed; it’s just one building block in the overarching system. (Location 575)
-
The subdomains have to interact with each other to achieve the company’s goals in its business domain. For example, Starbucks may be most recognized for its coffee, but building a successful coffeehouse chain requires more than just knowing how to make great coffee. You also have to buy or rent real estate at effective locations, hire personnel, and manage finances, among other activities. (Location 577)
-
Types of Subdomains (Location 581)
-
core subdomain is what a company does differently from its competitors. This may involve inventing new products or services or reducing costs by optimizing existing processes. (Location 584)
-
A core subdomain that is simple to implement can only provide a short-lived competitive advantage. Therefore, core subdomains are naturally complex. (Location 601)
-
important to note that core subdomains are not necessarily technical. Not all business problems are solved through algorithms or other technical solutions. A company’s competitive advantage can come from various sources. Consider, for example, a jewelry maker selling its products online. The online shop is important, but it’s not a core subdomain. The jewelry design is. (Location 610)
-
As a more intricate example, imagine a company that specializes in manual fraud detection. The company trains its analysts to go over questionable documents and flag potential fraud cases. You are building the software system the analysts are working with. Is it a core subdomain? No. The core subdomain is the work the analysts are doing. The system you are building has nothing to do with fraud analysis, it just displays the documents and tracks the analysts’ comments. (Location 617)
-
Generic subdomains are business activities that all companies are performing in the same way. Like core subdomains, generic subdomains are generally complex and hard to implement. However, generic subdomains do not provide any competitive edge for the company. There is no need for innovation or optimization here: battle-tested implementations are widely available, and all companies use them. (Location 633)
-
As the name suggests, supporting subdomains support the company’s business. However, contrary to core subdomains, supporting subdomains do not provide any competitive advantage. (Location 648)
-
The distinctive characteristic of supporting subdomains is the complexity of the solution’s business logic. Supporting subdomains are simple. Their business logic resembles mostly data entry screens and ETL (extract, transform, load) operations; that is, the so-called CRUD (create, read, update, and delete) interfaces. These activity areas do not provide any competitive advantage for the company, and therefore do not require high entry barriers. (Location 658)
-
Only core subdomains provide a competitive advantage to a company. Core subdomains are the company’s strategy for differentiating itself from its competitors. (Location 668)
-
Generic subdomains, by definition, cannot be a source for any competitive advantage. These are generic solutions—the same solutions used by the company and its competitors. (Location 676)
-
times it may be challenging to differentiate between core and supporting subdomains. Complexity is a useful guiding principle. Ask whether the subdomain in question can be turned into a side business. Would someone pay for it on its own? If so, this is a core subdomain. Similar (Location 712)
-
Another useful guiding principle for identifying software-related core subdomains is to evaluate the complexity of the business logic that you will have to model and implement in code. Does the business logic resemble CRUD interfaces for data entry, or do you have to implement complex algorithms or business processes orchestrated by complex business rules and invariants? In the former case, it’s a sign of a supporting subdomain, while the latter is a typical core subdomain. (Location 720)
-
solutions for core subdomains are emergent. Different implementations have to be tried out, refined, and optimized. Moreover, the work on core subdomains is never done. Companies continuously innovate and evolve core subdomains. (Location 735)
-
Core subdomains provide the company its ability to compete with other players in the industry. That’s a business-critical responsibility, but does it mean that supporting and generic subdomains are not important? Of course not. All subdomains are required for the company to work in its business domain. (Location 743)
-
Lack of competitive advantage makes it reasonable to avoid implementing supporting subdomains in-house. However, unlike generic subdomains, no ready-made solutions are available. So, a company has no choice but to implement supporting subdomains itself. That said, the simplicity of the business logic and infrequency of changes make it easy to cut corners. (Location 765)
-
Table 1-1. The differences between the three types of subdomains Subdomain type Competitive advantage Complexity Volatility Implementation Problem Core Yes High High In-house Interesting Generic No High Low Buy/ adopt Solved Supporting No Low Low In-house/ outsource Obvious Identifying Subdomain (Location 775)
-
But how do we actually identify the subdomains and their boundaries? The subdomains and their types are defined by the company’s business strategy: its business domains and how it differentiates itself to compete with other companies in the same field. In the vast majority of software projects, in one way or another the subdomains are “already there.” That doesn’t mean, however, that it is always easy and straightforward to identify their boundaries. (Location 784)
-
A good starting point is the company’s departments and other organizational units. For example, an online retail shop might include warehouse, customer service, picking, shipping, quality control, and channel management departments, among others. These, however, are relatively coarse-grained areas of activity. (Location 791)
-
Subdomains as coherent use cases From a technical perspective, subdomains resemble sets of interrelated, coherent use cases. Such sets of use cases usually involve the same actor, the business entities, and they all manipulate a closely related set of data. (Location 810)
-
We can use the definition of “subdomains as a set of coherent use cases” as a guiding principle for when to stop looking for finer-grained subdomains. These are the most precise boundaries of the subdomains. (Location 817)
-
Focus on the essentials Subdomains are a tool that alleviates the process of making software design decisions. All organizations likely have quite a few business functionalities that drive their competitive advantage but have nothing to do with software. The jewelry maker we discussed earlier in this chapter is but one example. When looking for subdomains, it’s important to identify business functions that are not related to software, acknowledge them as such, and focus on aspects of the business that are relevant to the software system you are working on. (Location 832)
-
Domain experts are subject matter experts who know all the intricacies of the business that we are going to model and implement in code. In other words, domain experts are knowledge authorities in the software’s business domain. (Location 910)
-
The domain experts are neither the analysts gathering the requirements nor the engineers designing the system. Domain experts represent the business. They are the people who identified the business problem in the first place and from whom all business knowledge originates. (Location 911)
-
As a rule of thumb, domain experts are either the people coming up with requirements or the software’s end users. The software is supposed to solve their problems. (Location 914)
-
The domain experts’ expertise can have different scopes. Some subject matter experts will have a detailed understanding of how the entire business domain operates, while others will specialize in particular subdomains. (Location 915)
-
For example, in an online advertising agency, the domain experts would be campaign managers, media buyers, analysts, and other business stakeholders. (Location 917)
-
Core subdomains The interesting problems. These are the activities the company is performing differently from its competitors and from which it gains its competitive advantage. (Location 921)
-
Generic subdomains The solved problems. These are the things all companies are doing in the same way. There is no room or need for innovation here; rather than creating in-house implementations, it’s more cost-effective to use existing solutions. (Location 923)
-
Supporting subdomains The problems with obvious solutions. These are the activities the company likely has to implement in-house, but that do not provide any competitive advantage. (Location 924)
-
To be effective, the software has to mimic the domain experts’ way of thinking about the problem—their mental models. Without an understanding of the business problem and the reasoning behind the requirements, our solutions will be limited to “translating” business requirements into source code. (Location 33)
-
Effective knowledge sharing between domain experts and software engineers requires effective communication. Let’s (Location 41)
-
Communication (Location 45)
-
During the traditional software development lifecycle, the domain knowledge is “translated” into an engineer-friendly form known as an analysis model, which is a description of the system’s requirements rather than an understanding of the business domain behind it. While the intentions may be good, such mediation is hazardous to knowledge sharing. In any translation, information is lost; in this case, domain knowledge that is essential for solving business problems gets lost on its way to the software engineers. (Location 55)
-
Such a software development process resembles the children’s game Telephone: 3 the message, or domain knowledge, often becomes distorted. The information leads to software engineers implementing the wrong solution, or the right solution but to the wrong problems. In either case, the outcome is the same: a failed software project. (Location 68)
-
What Is a Ubiquitous Language? (Location 74)
-
The idea is simple and straightforward: if parties need to communicate efficiently, instead of relying on translations, they have to speak the same language. (Location 82)
-
ubiquitous language is the language of the business. (Location 92)
-
As such, it should consist of business domain–related terms only. (Location 92)
-
The ubiquitous language must be precise and consistent. It should eliminate the need for assumptions and should make the business domain’s logic explicit. Since ambiguity hinders communication, each term of the ubiquitous language should have one and only one meaning. (Location 105)
-
Ambiguous terms Let’s say that in some business domain, the term policy has multiple meanings: it can mean a regulatory rule or an insurance contract. The exact meaning can be worked out in human-to-human interaction, depending on the context. Software, however, doesn’t cope well with ambiguity, and it can be cumbersome and challenging to model the “policy” entity in code. Ubiquitous language demands a single meaning for each term, so “policy” should be modeled explicitly using the two terms regulatory rule and insurance contract. (Location 108)
-
Two terms cannot be used interchangeably in a ubiquitous language. For example, many systems use the term user. However, a careful examination of the domain experts’ lingo may reveal that user and other terms are used interchangeably: for example, user, visitor, administrator, account, etc. (Location 113)
-
Synonymous terms can seem harmless at first. However, in most cases, they denote different concepts. In this example, both visitor and account technically refer to the system’s users; however, in most systems, unregistered and registered users represent different roles and have different behaviors. (Location 115)
-
A model is a simplified representation of a thing or phenomenon that intentionally emphasizes certain aspects while ignoring others. Abstraction with a specific use in mind. (Location 127)
-
A model is not a copy of the real world but a human construct that helps us make sense of real-world systems. A canonical example of a model is a map. Any map is a model, including navigation maps, terrain maps, world maps, subway maps, and others, as shown in (Location 132)
-
effective model contains only the details needed to fulfill its purpose. For example, you won’t see subway stops on a world map. On the other hand, you cannot use a subway map to estimate distances. Each map contains just the information it is supposed to provide. (Location 138)
-
This point is worth reiterating: a useful model is not a copy of the real world. Instead, a model is intended to solve a problem, and it should provide just enough information for that purpose. (Location 141)
-
The model is supposed to capture the domain experts’ mental models—their thought processes about how the business works to implement its function. (Location 154)
-
Tools (Location 174)
-
wiki can be used as a glossary to capture and document the ubiquitous language. Such a glossary alleviates the onboarding process of new team members, as it serves as a go-to place for information about the business domain’s terminology. (Location 178)
-
When a ubiquitous language is changed, all team members should be encouraged to go ahead and update the glossary. That’s contrary to a centralized approach, in which only team leaders or architects (Location 181)
-
As you gain experience in this practice, you will notice that frequently, this process involves not merely discovering knowledge that is already there, but rather co-creating the model in tandem with domain experts. There may be ambiguities and even white spots in domain experts’ own understanding of the business domain; for example, defining only the “happy path” scenarios but not considering edge cases that challenge the accepted assumptions. Furthermore, you may encounter business domain concepts that lack explicit definitions. (Location 207)
-
ubiquitous language to drive software design decisions, the language must be clear and consistent. It should be free of ambiguity, implicit assumptions, and extraneous details. (Location 946)
-
Inconsistent Models (Location 953)
-
The closer the implementations of the conflicting models are, the easier it is to make a mistake. Second, the implementation of the model won’t be aligned with the ubiquitous language. No one would use the prefixes in conversations. People don’t need this extra information; they can rely on the conversation’s context. (Location 981)
-
What Is a Bounded Context? (Location 987)
-
divide the ubiquitous language into multiple smaller languages, then assign each one to the explicit context in which it can be applied: its bounded context. (Location 987)
-
a sense, terminology conflicts and implicit contexts are an inherent part of any decent-sized business. With the bounded context pattern, the contexts are modeled as an explicit and integral part of the business domain. (Location 998)
-
Model Boundaries (Location 1000)
-
In other words, bounded contexts are the consistency boundaries of ubiquitous languages. A language’s terminology, principles, and business (Location 1009)
-
Bounded contexts allow us to complete the definition of a ubiquitous language. A ubiquitous language is not “ubiquitous” in the sense that it should be used and applied “ubiquitously” throughout the organization. A ubiquitous language is not universal. (Location 1011)
-
ubiquitous language is ubiquitous only in the boundaries of its bounded context. The language is focused on describing only the model that is encompassed by the bounded context. (Location 1013)
-
Boundaries can be wide, following the business domain’s inherent contexts, or narrow, further dividing the business domain into smaller problem domains. (Location 1026)
-
The reasons for extracting finer-grained bounded contexts out of a larger one include constituting new software engineering teams or addressing some of the system’s nonfunctional requirements; for example, when you need to separate the development lifecycles of some of the components originally residing in a single bounded context. Another common reason for extracting one functionality is the ability to scale it independently from the rest of the bounded context’s functionalities. (Location 1032)
-
Subdomains To comprehend a company’s business strategy, we have to analyze its business domain. According to domain-driven design methodology, the analysis phase involves identifying the different subdomains (core, supporting, and generic). That’s how the organization works and plans its competitive strategy. (Location 1055)
-
Bounded Contexts Bounded contexts, on the other hand, are designed. Choosing models’ boundaries is a strategic design decision. We decide how to divide the business domain into smaller, manageable problem domains. (Location 1060)
-
a single model could span the entire business domain. This strategy could work for a small system, as shown in Figure 3-5. Figure 3-5. Monolithic bounded context When conflicting models arise, we can follow the domain experts’ mental models and decompose the systems into bounded contexts, as shown in Figure 3-6. (Location 1063)
-
It’s crucial to remember that subdomains are discovered and bounded contexts are designed. 1 The subdomains are defined by the business strategy. However, we can design the software solution and its bounded contexts to address the specific project’s context and constraints. (Location 1076)
-
Boundaries (Location 1087)
-
The bounded context pattern is the domain-driven design tool for defining physical and ownership boundaries. (Location 1096)
-
Physical Boundaries (Location 1098)
-
Bounded contexts serve not only as model boundaries but also as physical boundaries of the systems implementing them. Each bounded context should be implemented as an individual service/ project, meaning it is implemented, evolved, and versioned independently of other bounded contexts. (Location 1098)
-
Ownership Boundaries (Location 1108)
-
In software projects, we can leverage model boundaries—bounded contexts—for the peaceful coexistence of teams. The division of work between teams is another strategic decision that can be made using the bounded context pattern. (Location 1112)
-
bounded context should be implemented, evolved, and maintained by one team only. No two teams can work on the same bounded context. This segregation eliminates implicit assumptions that teams might make about one another’s models. Instead, they have to define communication protocols for integrating their models and systems explicitly. (Location 1113)
-
relationship between teams and bounded contexts is one-directional: a bounded context should be owned by only one team. However, a single team can own multiple bounded contexts, as Figure 3-8 illustrates. (Location 1116)
-
A semantic domain is defined as an area of meaning and the words used to talk about it. For example, the words monitor, port, and processor have different meanings in the software and hardware engineering semantic domains. (Location 1135)
New highlights added 08-08-2024 at 8:22 AM
Chapter 4. Integrating Bounded Contexts (Location 1213)
the components have to interact with one another to achieve the system’s overarching goals—so, too, do the implementations in bounded contexts. Although they can evolve independently, they have to integrate with one another. As a result, there will always be touchpoints between bounded contexts. These are called contracts. (Location 1225)
Cooperation (Location 1234)
Cooperation patterns relate to bounded contexts implemented by teams with well-established communication. In the simplest case, these are bounded contexts implemented by a single team. This also applies to teams with dependent goals, where one team’s success depends on the success of the other, and vice versa. Again, the main criterion here is the quality of the teams’ communication and collaboration. (Location 1234)
Partnership (Location 1245)
the partnership model, the integration between bounded contexts is coordinated in an ad hoc manner. One team can notify a second team about a change in the API, and the second team will cooperate and adapt—no drama or conflicts (Location 1245)
The coordination of integration here is two-way. No one team dictates the language that is used for defining the contracts. The teams can work out the differences and choose the most appropriate solution. Also, both sides cooperate in solving any integration issues that might come up. Neither team is interested in blocking the other one. (Location 1253)
Well-established collaboration practices, high levels of commitment, and frequent synchronizations between teams are required for successful integration in this manner. (Location 1255)
This pattern might not be a good fit for geographically distributed teams since it may present synchronization and communication challenges. (Location 1257)
Shared Kernel (Location 1259)
bounded contexts being model boundaries, there still can be cases when the same model of a subdomain, or a part of it, will be implemented in multiple bounded contexts. It’s crucial to stress that the shared model is designed according to the needs of all of the bounded contexts. Moreover, the shared model has to be consistent across all of the bounded contexts that are using it. (Location 1259)
Implementation (Location 1276)
If the organization uses the mono-repository approach, these can be the same source files referenced by multiple bounded contexts. (Location 1278)
If using a shared repository is not possible, the shared kernel can be extracted into a dedicated project and referenced in the bounded contexts as a linked library. Either way, each change to the shared kernel must trigger integration tests for all the affected bounded contexts. (Location 1279)
When to use shared kernel (Location 1284)
The overarching applicability criterion for the shared kernel pattern is the cost of duplication versus the cost of coordination. Since the pattern introduces a strong dependency between the participating bounded contexts, it should be applied only when the cost of duplication is higher than the cost of coordination—in (Location 1284)
Another common use case for applying the shared kernel pattern, albeit a temporary one, is the gradual modernization of a legacy system. In such a scenario, the shared codebase can be a pragmatic intermediate solution for gradually decomposing the system into bounded contexts. (Location 1298)
Finally, a shared kernel can be a good fit for integrating bounded contexts owned and implemented by the same team. In such a case, an ad hoc integration of the bounded contexts—a partnership—can “wash out” the contexts’ boundaries over time. A shared kernel can be used for explicitly defining (Location 1300)
Customer–Supplier (Location 1310)
Unlike in the cooperation case, both teams (upstream and downstream) can succeed independently. Consequently, in most cases we have an imbalance of power: either the upstream or the downstream team can dictate the integration contract. (Location 1321)
Conformist (Location 1325)
In some cases, the balance of power favors the upstream team, which has no real motivation to support its clients’ needs. Instead, it just provides the integration contract, defined according to its own model—take it or leave it. Such power imbalances can be caused by integration with service providers that are external to the organization or simply by organizational politics. If the downstream team can accept the upstream team’s model, the bounded contexts’ relationship is called conformist. The downstream conforms to the upstream bounded context’s model, as shown in (Location 1325)
The downstream team’s decision to give up some of its autonomy can be justified in multiple ways. For example, the contract exposed by the upstream team may be an industry-standard, well-established model, or it may just be good enough for the downstream team’s needs. (Location 1334)
Anticorruption Layer (Location 1337)
As in the conformist pattern, the balance of power in this relationship is still skewed toward the upstream service. However, in this case, the downstream bounded context is not willing to conform. Instead, it can translate the upstream bounded context’s model into a model tailored to its own needs via an anticorruption layer, as shown in Figure 4-5. (Location 1337)
The anticorruption layer pattern addresses scenarios in which it is not desirable or worth the effort to conform to the supplier’s model, such as the following: (Location 1345)
When the downstream bounded context contains a core subdomain (Location 1346)
When the upstream model is inefficient or inconvenient for the consumer’s needs (Location 1348)
When the supplier’s contract changes often (Location 1349)
Open-Host Service (Location 1354)
This pattern addresses cases in which the power is skewed toward the consumers. The supplier is interested in protecting its consumers and providing the best service possible. (Location 1354)
To protect the consumers from changes in its implementation model, the upstream supplier decouples the implementation model from the public interface. This decoupling allows the supplier to evolve its implementation and public models at different rates, (Location 1359)
The supplier’s public interface is not intended to conform to its ubiquitous language. Instead, it is intended to expose a protocol convenient for the consumers, expressed in an integration-oriented language. As such, the public protocol is called the published language. In a sense, the open-host service pattern is a reversal (Location 1362)
Decoupling the bounded context’s implementation and integration models gives the upstream bounded context the freedom to evolve its implementation without affecting the downstream contexts. Of course, that’s only possible if the modified implementation model can be translated into the published language the consumers are already using. Furthermore, (Location 1368)
The last collaboration option is not to collaborate at all. This pattern can arise for different reasons, in cases where the teams are unwilling or unable to collaborate. We’ll look at a few of them here. (Location 1378)
Communication Issues (Location 1387)
common reason for avoiding collaboration is communication difficulties driven by the organization’s size or internal politics. When teams have a hard time collaborating and agreeing, it may be more cost-effective to go their separate ways and duplicate functionality in multiple bounded contexts. (Location 1387)
Generic Subdomains (Location 1393)
The nature of the duplicated subdomain can also be a reason for teams to go their separate ways. When the subdomain in question is generic, and if the generic solution is easy to integrate, it may be more cost-effective to integrate it locally in each bounded context. An example is a logging framework; it would make little sense for one of the bounded contexts to expose it as a service. The (Location 1393)
Model Differences (Location 1401)
Differences in the bounded contexts’ models can also be a reason to go with a separate ways collaboration. The models may be so different that a conformist relationship is impossible, and implementing an anticorruption layer would be more expensive than duplicating the functionality. In such a case, it is again more cost-effective for the teams to go their separate ways. (Location 1401)
Context Map (Location 1410)
context map is a visual representation of the system’s bounded contexts and the integrations between them. This visual notation gives valuable strategic insight on multiple levels: (Location 1414)
High-level design A context map provides an overview of the system’s components and the models they implement. Communication patterns A context map depicts the communication patterns among teams—for example, which teams are collaborating and which prefer “less intimate” integration patterns, such as the anticorruption layer and separate ways patterns. Organizational issues A context map can give insight into organizational issues. For example, what does it mean if a certain upstream team’s downstream consumers all resort to implementing an anticorruption layer, or if all implementations of the separate ways pattern are concentrated around the same team? (Location 1416)
even if bounded contexts are limited to a single subdomain, there still can be multiple integration patterns at play—for example, if the subdomains’ modules require different integration strategies. (Location 1435)
New highlights added 14-08-2024 at 8:53 AM
To be effective, the software has to mimic the domain experts’ way of thinking about the problem— their mental models. Without an understanding of the business problem and the reasoning behind the requirements, our solutions will be limited to “translating” business requirements into source code. (Location 33)
During the traditional software development lifecycle, the domain knowledge is “translated” into an engineer- friendly form known as an analysis model, which is a description of the system’s requirements rather than an understanding of the business domain behind it. While the intentions may be good, such mediation is hazardous to knowledge sharing. In any translation, information is lost; in this case, domain knowledge that is essential for solving business problems gets lost on its way to the software engineers. (Location 55)
As such, it should consist of business domain– related terms only. (Location 92)
Ambiguous terms Let’s say that in some business domain, the term policy has multiple meanings: it can mean a regulatory rule or an insurance contract. The exact meaning can be worked out in human- to- human interaction, depending on the context. Software, however, doesn’t cope well with ambiguity, and it can be cumbersome and challenging to model the “policy” entity in code. Ubiquitous language demands a single meaning for each term, so “policy” should be modeled explicitly using the two terms regulatory rule and insurance contract. (Location 108)
A model is not a copy of the real world but a human construct that helps us make sense of real- world systems. A canonical example of a model is a map. Any map is a model, including navigation maps, terrain maps, world maps, subway maps, and others, as shown in (Location 132)
The model is supposed to capture the domain experts’ mental models— their thought processes about how the business works to implement its function. (Location 154)
wiki can be used as a glossary to capture and document the ubiquitous language. Such a glossary alleviates the onboarding process of new team members, as it serves as a go- to place for information about the business domain’s terminology. (Location 178)
As you gain experience in this practice, you will notice that frequently, this process involves not merely discovering knowledge that is already there, but rather co- creating the model in tandem with domain experts. There may be ambiguities and even white spots in domain experts’ own understanding of the business domain; for example, defining only the “happy path” scenarios but not considering edge cases that challenge the accepted assumptions. Furthermore, you may encounter business domain concepts that lack explicit definitions. (Location 207)
The strategic tools of DDD are used to analyze business domains and strategy, and to foster a shared understanding of the business between the different stakeholders. We will also use this knowledge of the business domain to drive high- level design decisions: decomposing systems into components and defining their integration patterns. (Location 505)
The strategic aspect of DDD deals with answering the questions of “what?” and “why?”— what software we are building and why we are building it. The tactical part is all about the “how”— how each component is implemented. (Location 531)
A subdomain is a fine- grained area of business activity. All of a company’s subdomains form its business domain: the service it provides to its customers. Implementing a single subdomain is not enough for a company to succeed; it’s just one building block in the overarching system. (Location 575)
A core subdomain that is simple to implement can only provide a short- lived competitive advantage. Therefore, core subdomains are naturally complex. (Location 601)
Generic subdomains are business activities that all companies are performing in the same way. Like core subdomains, generic subdomains are generally complex and hard to implement. However, generic subdomains do not provide any competitive edge for the company. There is no need for innovation or optimization here: battle- tested implementations are widely available, and all companies use them. (Location 633)
The distinctive characteristic of supporting subdomains is the complexity of the solution’s business logic. Supporting subdomains are simple. Their business logic resembles mostly data entry screens and ETL (extract, transform, load) operations; that is, the so- called CRUD (create, read, update, and delete) interfaces. These activity areas do not provide any competitive advantage for the company, and therefore do not require high entry barriers. (Location 658)
Generic subdomains, by definition, cannot be a source for any competitive advantage. These are generic solutions— the same solutions used by the company and its competitors. (Location 676)
Another useful guiding principle for identifying software- related core subdomains is to evaluate the complexity of the business logic that you will have to model and implement in code. Does the business logic resemble CRUD interfaces for data entry, or do you have to implement complex algorithms or business processes orchestrated by complex business rules and invariants? In the former case, it’s a sign of a supporting subdomain, while the latter is a typical core subdomain. (Location 720)
Core subdomains provide the company its ability to compete with other players in the industry. That’s a business- critical responsibility, but does it mean that supporting and generic subdomains are not important? Of course not. All subdomains are required for the company to work in its business domain. (Location 743)
Lack of competitive advantage makes it reasonable to avoid implementing supporting subdomains in- house. However, unlike generic subdomains, no ready- made solutions are available. So, a company has no choice but to implement supporting subdomains itself. That said, the simplicity of the business logic and infrequency of changes make it easy to cut corners. (Location 765)
Table 1- 1. The differences between the three types of subdomains Subdomain type Competitive advantage Complexity Volatility Implementation Problem Core Yes High High In- house Interesting Generic No High Low Buy/ adopt Solved Supporting No Low Low In- house/ outsource Obvious Identifying Subdomain (Location 775)
A good starting point is the company’s departments and other organizational units. For example, an online retail shop might include warehouse, customer service, picking, shipping, quality control, and channel management departments, among others. These, however, are relatively coarse- grained areas of activity. (Location 791)
We can use the definition of “subdomains as a set of coherent use cases” as a guiding principle for when to stop looking for finer- grained subdomains. These are the most precise boundaries of the subdomains. (Location 817)
Generic subdomains The solved problems. These are the things all companies are doing in the same way. There is no room or need for innovation here; rather than creating in- house implementations, it’s more cost- effective to use existing solutions. (Location 923)
Supporting subdomains The problems with obvious solutions. These are the activities the company likely has to implement in- house, but that do not provide any competitive advantage. (Location 924)
a sense, terminology conflicts and implicit contexts are an inherent part of any decent- sized business. With the bounded context pattern, the contexts are modeled as an explicit and integral part of the business domain. (Location 998)
The reasons for extracting finer- grained bounded contexts out of a larger one include constituting new software engineering teams or addressing some of the system’s nonfunctional requirements; for example, when you need to separate the development lifecycles of some of the components originally residing in a single bounded context. Another common reason for extracting one functionality is the ability to scale it independently from the rest of the bounded context’s functionalities. (Location 1032)
Subdomains To comprehend a company’s business strategy, we have to analyze its business domain. According to domain- driven design methodology, the analysis phase involves identifying the different subdomains (core, supporting, and generic). That’s how the organization works and plans its competitive strategy. (Location 1055)
a single model could span the entire business domain. This strategy could work for a small system, as shown in Figure 3- 5. Figure 3- 5. Monolithic bounded context When conflicting models arise, we can follow the domain experts’ mental models and decompose the systems into bounded contexts, as shown in Figure 3- 6. (Location 1063)
The bounded context pattern is the domain- driven design tool for defining physical and ownership boundaries. (Location 1096)
In software projects, we can leverage model boundaries— bounded contexts— for the peaceful coexistence of teams. The division of work between teams is another strategic decision that can be made using the bounded context pattern. (Location 1112)
relationship between teams and bounded contexts is one- directional: a bounded context should be owned by only one team. However, a single team can own multiple bounded contexts, as Figure 3- 8 illustrates. (Location 1116)
the components have to interact with one another to achieve the system’s overarching goals— so, too, do the implementations in bounded contexts. Although they can evolve independently, they have to integrate with one another. As a result, there will always be touchpoints between bounded contexts. These are called contracts. (Location 1225)
Cooperation patterns relate to bounded contexts implemented by teams with well- established communication. In the simplest case, these are bounded contexts implemented by a single team. This also applies to teams with dependent goals, where one team’s success depends on the success of the other, and vice versa. Again, the main criterion here is the quality of the teams’ communication and collaboration. (Location 1234)
the partnership model, the integration between bounded contexts is coordinated in an ad hoc manner. One team can notify a second team about a change in the API, and the second team will cooperate and adapt— no drama or conflicts (Location 1245)
The coordination of integration here is two- way. No one team dictates the language that is used for defining the contracts. The teams can work out the differences and choose the most appropriate solution. Also, both sides cooperate in solving any integration issues that might come up. Neither team is interested in blocking the other one. (Location 1253)
Well- established collaboration practices, high levels of commitment, and frequent synchronizations between teams are required for successful integration in this manner. (Location 1255)
If the organization uses the mono- repository approach, these can be the same source files referenced by multiple bounded contexts. (Location 1278)
The overarching applicability criterion for the shared kernel pattern is the cost of duplication versus the cost of coordination. Since the pattern introduces a strong dependency between the participating bounded contexts, it should be applied only when the cost of duplication is higher than the cost of coordination— in (Location 1284)
Finally, a shared kernel can be a good fit for integrating bounded contexts owned and implemented by the same team. In such a case, an ad hoc integration of the bounded contexts— a partnership— can “wash out” the contexts’ boundaries over time. A shared kernel can be used for explicitly defining (Location 1300)
Customer– Supplier (Location 1310)
In some cases, the balance of power favors the upstream team, which has no real motivation to support its clients’ needs. Instead, it just provides the integration contract, defined according to its own model— take it or leave it. Such power imbalances can be caused by integration with service providers that are external to the organization or simply by organizational politics. If the downstream team can accept the upstream team’s model, the bounded contexts’ relationship is called conformist. The downstream conforms to the upstream bounded context’s model, as shown in (Location 1325)
The downstream team’s decision to give up some of its autonomy can be justified in multiple ways. For example, the contract exposed by the upstream team may be an industry- standard, well- established model, or it may just be good enough for the downstream team’s needs. (Location 1334)
As in the conformist pattern, the balance of power in this relationship is still skewed toward the upstream service. However, in this case, the downstream bounded context is not willing to conform. Instead, it can translate the upstream bounded context’s model into a model tailored to its own needs via an anticorruption layer, as shown in Figure 4- 5. (Location 1337)
Open- Host Service (Location 1354)
The supplier’s public interface is not intended to conform to its ubiquitous language. Instead, it is intended to expose a protocol convenient for the consumers, expressed in an integration- oriented language. As such, the public protocol is called the published language. In a sense, the open- host service pattern is a reversal (Location 1362)
common reason for avoiding collaboration is communication difficulties driven by the organization’s size or internal politics. When teams have a hard time collaborating and agreeing, it may be more cost- effective to go their separate ways and duplicate functionality in multiple bounded contexts. (Location 1387)
The nature of the duplicated subdomain can also be a reason for teams to go their separate ways. When the subdomain in question is generic, and if the generic solution is easy to integrate, it may be more cost- effective to integrate it locally in each bounded context. An example is a logging framework; it would make little sense for one of the bounded contexts to expose it as a service. The (Location 1393)
Differences in the bounded contexts’ models can also be a reason to go with a separate ways collaboration. The models may be so different that a conformist relationship is impossible, and implementing an anticorruption layer would be more expensive than duplicating the functionality. In such a case, it is again more cost- effective for the teams to go their separate ways. (Location 1401)
High- level design A context map provides an overview of the system’s components and the models they implement. Communication patterns A context map depicts the communication patterns among teams— for example, which teams are collaborating and which prefer “less intimate” integration patterns, such as the anticorruption layer and separate ways patterns. Organizational issues A context map can give insight into organizational issues. For example, what does it mean if a certain upstream team’s downstream consumers all resort to implementing an anticorruption layer, or if all implementations of the separate ways pattern are concentrated around the same team? (Location 1416)
even if bounded contexts are limited to a single subdomain, there still can be multiple integration patterns at play— for example, if the subdomains’ modules require different integration strategies. (Location 1435)
Part II. Tactical Design
Chapter 5. Implementing Simple Business Logic (Location 1477)
Transaction Script Organizes business logic by procedures where each procedure handles a single request from the presentation.— Martin Fowler1 (Location 1486)
A system’s public interface can be seen as a collection of business transactions that consumers can execute, as shown in Figure 5- 1. These transactions can retrieve information managed by the system, modify it, or both. The pattern organizes the system’s business logic based on procedures, where each procedure implements an operation that is executed by the system’s consumer via its public interface. In effect, the system’s public operations are used as encapsulation boundaries. (Location 1491)
Implementation (Location 1497)
Each procedure is implemented as a simple, straightforward procedural script. It can use a thin abstraction layer for integrating with storage mechanisms, but it is also free to access the databases directly. The only requirement procedures have to fulfill is transactional behavior. Each operation should either succeed or fail but can never result in an invalid state. Even if execution of a transaction script fails at the most inconvenient moment, the system should remain consistent— either by rolling back any changes it has made up until the failure or by executing compensating actions. The transactional behavior is reflected in the pattern’s name: transaction script. (Location 1497)
When to Use Transaction Script (Location 1622)
The transaction script pattern is well adapted to the most straightforward problem domains in which the business logic resembles simple procedural operations. For example, in extract- transform- load (ETL) operations, each operation extracts data from a source, applies transformation logic to convert it into another form, and loads the result into the destination store. (Location 1622)
The transaction script pattern naturally fits supporting subdomains where, by definition, the business logic is simple. It can also be used as an adapter for integration with external systems— for example, generic subdomains, or as a part of an anticorruption layer (Location 1631)
The main advantage of the transaction script pattern is its simplicity. It introduces minimal abstractions and minimizes the overhead both in runtime performance and in understanding the business logic. That said, this simplicity is also the pattern’s disadvantage. The more complex the business logic gets, the more it’s prone to duplicate business logic across transactions, and consequently, to result in inconsistent behavior— when the duplicated code goes out of sync. As a result, transaction script should never be used for core subdomains, as this pattern won’t cope with the high complexity of a core subdomain’s business logic. (Location 1633)
An object that wraps a row in a database table or view, encapsulates the database access, and adds domain logic on that data.— Martin Fowler2 Like the transaction script pattern, active record supports cases where the business logic is simple. Here, however, the business logic may operate on more complex data structures. (Location 1645)
Implementation Consequently, this pattern uses dedicated objects, known as active records, to represent complicated data structures. Apart from the data structure, these objects also implement data access methods for creating, reading, updating, and deleting records— the so- called CRUD operations. As a result, the active record objects are coupled to an object- relational mapping (ORM) or some other data access framework. The pattern’s name is derived from the fact that each data (Location 1654)
The pattern’s goal is to encapsulate the complexity of mapping the in- memory object to the database’s schema. In addition to being responsible for persistence, the active record objects can contain business logic; for example, validating new values assigned to the fields, or even implementing business- related procedures that manipulate an object’s data. That said, the distinctive feature of an active record object is the separation of data structures and behavior (business logic). Usually, an active record’s fields have public getters and setters that allow external procedures to modify its (Location 1677)
When to Use Active Record (Location 1682)
Because an active record is essentially a transaction script that optimizes access to databases, this pattern can only support relatively simple business logic, such as CRUD operations, which, at most, validate the user’s input. (Location 1682)
Accordingly, as in the case of the transaction script pattern, the active record pattern lends itself to supporting subdomains, integration of external solutions for generic subdomains, or model transformation tasks. The difference between the patterns is that active record addresses the complexity of mapping complicated data structures to a database’s schema. (Location 1685)
The active record pattern is also known as an anemic domain model antipattern; in other words, an improperly designed domain model. (Location 1688)
Domain Model
Here, instead of CRUD interfaces, we deal with complicated state transitions, business rules, and invariants: rules that have to be protected at all times. (Location 1767)
Implementation (Location 1780)
A domain model is an object model of the domain that incorporates both behavior and data. 1 DDD’s tactical patterns— aggregates, value objects, domain events, and domain services— are the building blocks of such an object model. (Location 1780)
All of these patterns share a common theme: they put the business logic first. Let’s see how the domain model addresses different design concerns. (Location 1785)
Complexity The domain’s business logic is already inherently complex, so the objects used for modeling it should not introduce any additional accidental complexities. The model should be devoid of any infrastructural or technological concerns, such as implementing calls to databases or other external components of the system. This restriction requires the model’s objects to be plain old objects, objects implementing business logic without relying on or directly incorporating any infrastructural components or frameworks. (Location 1787)
Building Blocks (Location 1798)
Value object A value object is an object that can be identified by the composition of its values. For example, consider a color object: class Color { int _red; int _green; int _blue; } The composition of the values of the three fields red, green, and blue defines a color. Changing the value of one of the fields will result in a new color. No two colors can have the same values. Also, two instances of the same color must have the same values. (Location 1799)
In the preceding implementation of the Person class, most of the values are of type String and they are assigned based on convention. For example, the input to the landlinePhone should be a valid landline phone number, and the countryCode should be a valid, two- letter, uppercased country code. Of course, the system cannot trust the user to always supply correct values, and as a result, the class has to validate all input fields. This approach presents multiple design risks. First, the validation logic tends to be duplicated. Second, it’s hard to enforce calling the validation logic before the values are used. It will become even more challenging in the future, when the codebase will be evolved by other engineers. Compare the following alternative design of the same object, this time leveraging value objects: class Person { private PersonId _id; private Name _name; private PhoneNumber _landline; private PhoneNumber _mobile; private EmailAddress _email; private Height _height; private CountryCode _country; public Person(…) { … } } static void Main( string[] args) { var dave = new Person( id: new PersonId( 30217), name: new Name(” Dave”, “Ancelovici”), landline: PhoneNumber.Parse(” 023745001”), mobile: PhoneNumber.Parse(” 0873712503”), email: Email.Parse(” dave@ learning- ddd.com”), height: Height.FromMetric( 180), country: CountryCode.Parse(” BG”)); } First, notice the increased clarity. Take, for example, the country variable. There is no need to elaborately call it “countryCode” to communicate the intent of it holding a country code and not, for example, a full country name. The value object makes the intent clear, even with shorter variable names. (Location 1835)
Second, there is no need to validate the values before the assignment, as the validation logic resides in the value objects themselves. However, a value object’s behavior is not limited to mere validation. Value objects shine brightest when they centralize the business logic that manipulates the values. The cohesive logic is implemented in one place and is easy to test. Most importantly, value objects express the business domain’s concepts: they make the code speak the ubiquitous language. Let’s (Location 1863)
Implementation Since a change to any of the fields of a value object results in a different value, value objects are implemented as immutable objects. A change to one of the value object’s fields conceptually creates a different value— a different instance of a value object. Therefore, when an executed action results in a new value, as in the following case, which uses the MixWith method, it doesn’t modify the original instance but instantiates and returns a new one: (Location 1899)
When to use value objects The simple answer is, whenever you can. Not only do value objects make the code more expressive and encapsulate business logic that tends to spread apart, but the pattern makes the code safer. Since value objects are immutable, the value objects’ behavior is free of side effects and is thread safe. (Location 1952)
Entities (Location 1964)
An entity is the opposite of a value object. It requires an explicit identification field to distinguish between the different instances of the entity. A trivial example of an entity is a person. (Location 1964)
The central requirement for the identification field is that it should be unique for each instance of the entity: for each person, in our case (Figure 6- 2). Furthermore, except for very rare exceptions, the value of an entity’s identification field should remain immutable throughout the entity’s lifecycle. This brings us to the second conceptual difference between value objects and entities. (Location 1988)
- Note: Add a graph
Contrary to value objects, entities are not immutable and are expected to change. (Location 1993)
Aggregates (Location 2000)
An aggregate is an entity: it requires an explicit identification field and its state is expected to change during an instance’s lifecycle. However, it is much more than just an entity. The goal of the pattern is to protect the consistency of its data. Since an aggregate’s data is mutable, there are implications and challenges that the pattern has to address to keep its state consistent at all times. (Location 2000)
To enforce consistency of the data, the aggregate pattern draws a clear boundary between the aggregate and its outer scope: the aggregate is a consistency enforcement boundary. The aggregate’s logic has to validate all incoming modifications and ensure that the changes do not contradict its business rules. (Location 2015)
From an implementation perspective, the consistency is enforced by allowing only the aggregate’s business logic to modify its state. All processes or objects external to the aggregate are only allowed to read the aggregate’s state. Its state can only be mutated by executing corresponding methods of the aggregate’s public interface. (Location 2017)
An aggregate’s public interface is responsible for validating the input and enforcing all of the relevant business rules and invariants. This strict boundary also ensures that all business logic related to the aggregate is implemented in one place: the aggregate itself. (Location 2041)
It’s vital to protect the consistency of an aggregate’s state. 8 If multiple processes are concurrently updating the same aggregate, we have to prevent the latter transaction from blindly overwriting the changes committed by the first one. In such a case, the second process has to be notified that the state on which it had based its decisions is out of date, and it has to retry the operation. (Location 2060)
Transaction boundary Since an aggregate’s state can only be modified by its own business logic, the aggregate also acts as a transactional boundary. All changes to the aggregate’s state should be committed transactionally as one atomic operation. If an aggregate’s state is modified, either all the changes are committed or none of them is. (Location 2079)
The one aggregate instance per transaction forces us to carefully design an aggregate’s boundaries, ensuring that the design addresses the business domain’s invariants and rules. The need to commit changes in multiple aggregates signals a wrong transaction boundary, and hence, wrong aggregate boundaries. (Location 2085)
hierarchy contains both entities and value objects, and all of them belong to the same aggregate if they are bound by the domain’s business logic. That’s why the pattern is named “aggregate”: it aggregates business entities and value objects that belong to the same transaction boundary. (Location 2098)
The aggregate ensures that all the conditions are checked against strongly consistent data, and it won’t change after the checks are completed by ensuring that all changes to the aggregate’s data are performed as one atomic transaction. (Location 2125)
tags:
- source
- todo
Created Date: 2024-08-22
Author: - Vlad Khononov
URL: ---

Highlights
Context Map (Location 1410)
High- level design A context map provides an overview of the system’s components and the models they implement. Communication patterns A context map depicts the communication patterns among teams— for example, which teams are collaborating and which prefer “less intimate” integration patterns, such as the anticorruption layer and separate ways patterns. Organizational issues A context map can give insight into organizational issues. For example, what does it mean if a certain upstream team’s downstream consumers all resort to implementing an anticorruption layer, or if all implementations of the separate ways pattern are concentrated around the same team? (Location 1416)
even if bounded contexts are limited to a single subdomain, there still can be multiple integration patterns at play— for example, if the subdomains’ modules require different integration strategies. (Location 1435)
Part II. Tactical Design (Location 1461)
Chapter 5. Implementing Simple Business Logic (Location 1477)
Transaction Script Organizes business logic by procedures where each procedure handles a single request from the presentation.— Martin Fowler1 (Location 1486)
A system’s public interface can be seen as a collection of business transactions that consumers can execute, as shown in Figure 5- 1. These transactions can retrieve information managed by the system, modify it, or both. The pattern organizes the system’s business logic based on procedures, where each procedure implements an operation that is executed by the system’s consumer via its public interface. In effect, the system’s public operations are used as encapsulation boundaries. (Location 1491)
Implementation (Location 1497)
- Note: Add a graph
tags:
- source
- todo
Created Date: 2024-08-22
Author: - Vlad Khononov
URL: ---
Highlights
To be effective, the software has to mimic the domain experts’ way of thinking about the problem—their mental models. Without an understanding of the business problem and the reasoning behind the requirements, our solutions will be limited to “translating” business requirements into source code. (Location 33)
Effective knowledge sharing between domain experts and software engineers requires effective communication. Let’s (Location 41)
Communication (Location 45)
During the traditional software development lifecycle, the domain knowledge is “translated” into an engineer-friendly form known as an analysis model, which is a description of the system’s requirements rather than an understanding of the business domain behind it. While the intentions may be good, such mediation is hazardous to knowledge sharing. In any translation, information is lost; in this case, domain knowledge that is essential for solving business problems gets lost on its way to the software engineers. (Location 55)
Such a software development process resembles the children’s game Telephone:3 the message, or domain knowledge, often becomes distorted. The information leads to software engineers implementing the wrong solution, or the right solution but to the wrong problems. In either case, the outcome is the same: a failed software project. (Location 68)
What Is a Ubiquitous Language? (Location 74)
The idea is simple and straightforward: if parties need to communicate efficiently, instead of relying on translations, they have to speak the same language. (Location 82)
As such, it should consist of business domain–related terms only. (Location 92)
The ubiquitous language must be precise and consistent. It should eliminate the need for assumptions and should make the business domain’s logic explicit. Since ambiguity hinders communication, each term of the ubiquitous language should have one and only one meaning. (Location 105)
Ambiguous terms Let’s say that in some business domain, the term policy has multiple meanings: it can mean a regulatory rule or an insurance contract. The exact meaning can be worked out in human-to-human interaction, depending on the context. Software, however, doesn’t cope well with ambiguity, and it can be cumbersome and challenging to model the “policy” entity in code. Ubiquitous language demands a single meaning for each term, so “policy” should be modeled explicitly using the two terms regulatory rule and insurance contract. (Location 108)
Two terms cannot be used interchangeably in a ubiquitous language. For example, many systems use the term user. However, a careful examination of the domain experts’ lingo may reveal that user and other terms are used interchangeably: for example, user, visitor, administrator, account, etc. (Location 113)
Synonymous terms can seem harmless at first. However, in most cases, they denote different concepts. In this example, both visitor and account technically refer to the system’s users; however, in most systems, unregistered and registered users represent different roles and have different behaviors. (Location 115)
A model is a simplified representation of a thing or phenomenon that intentionally emphasizes certain aspects while ignoring others. Abstraction with a specific use in mind. (Location 127)
A model is not a copy of the real world but a human construct that helps us make sense of real-world systems. A canonical example of a model is a map. Any map is a model, including navigation maps, terrain maps, world maps, subway maps, and others, as shown in (Location 132)
effective model contains only the details needed to fulfill its purpose. For example, you won’t see subway stops on a world map. On the other hand, you cannot use a subway map to estimate distances. Each map contains just the information it is supposed to provide. (Location 138)
This point is worth reiterating: a useful model is not a copy of the real world. Instead, a model is intended to solve a problem, and it should provide just enough information for that purpose. (Location 141)
The model is supposed to capture the domain experts’ mental models—their thought processes about how the business works to implement its function. (Location 154)
Tools (Location 174)
wiki can be used as a glossary to capture and document the ubiquitous language. Such a glossary alleviates the onboarding process of new team members, as it serves as a go-to place for information about the business domain’s terminology. (Location 178)
When a ubiquitous language is changed, all team members should be encouraged to go ahead and update the glossary. That’s contrary to a centralized approach, in which only team leaders or architects (Location 181)
As you gain experience in this practice, you will notice that frequently, this process involves not merely discovering knowledge that is already there, but rather co-creating the model in tandem with domain experts. There may be ambiguities and even white spots in domain experts’ own understanding of the business domain; for example, defining only the “happy path” scenarios but not considering edge cases that challenge the accepted assumptions. Furthermore, you may encounter business domain concepts that lack explicit definitions. (Location 207)
According to studies, approximately 70% of software projects are not delivered on time, on budget, or according to the client’s requirements. In other words, the vast majority of software projects fail. This issue is so deep and widespread that we even have a term for it: software crisis. (Location 490)
The strategic tools of DDD are used to analyze business domains and strategy, and to foster a shared understanding of the business between the different stakeholders. We will also use this knowledge of the business domain to drive high-level design decisions: decomposing systems into components and defining their integration patterns. (Location 505)
DDD’s tactical patterns allow us to write code in a way that reflects the business domain, addresses its goals, and speaks the language of the business. (Location 508)
The strategic aspect of DDD deals with answering the questions of “what?” and “why?”—what software we are building and why we are building it. The tactical part is all about the “how”—how each component is implemented. (Location 531)
business domain defines a company’s main area of activity. Generally speaking, it’s the service the company provides to its clients. For example: FedEx provides courier delivery. Starbucks is best known for its coffee. Walmart is one of the most widely recognized retail establishments. (Location 564)
A company can operate in multiple business domains. For example, Amazon provides both retail and cloud computing services. (Location 568)
A subdomain is a fine-grained area of business activity. All of a company’s subdomains form its business domain: the service it provides to its customers. Implementing a single subdomain is not enough for a company to succeed; it’s just one building block in the overarching system. (Location 575)
The subdomains have to interact with each other to achieve the company’s goals in its business domain. For example, Starbucks may be most recognized for its coffee, but building a successful coffeehouse chain requires more than just knowing how to make great coffee. You also have to buy or rent real estate at effective locations, hire personnel, and manage finances, among other activities (Location 577)
Types of Subdomains (Location 581)
core subdomain is what a company does differently from its competitors. This may involve inventing new products or services or reducing costs by optimizing existing processes. (Location 584)
A core subdomain that is simple to implement can only provide a short-lived competitive advantage. Therefore, core subdomains are naturally complex. (Location 601)
important to note that core subdomains are not necessarily technical. Not all business problems are solved through algorithms or other technical solutions. A company’s competitive advantage can come from various sources. Consider, for example, a jewelry maker selling its products online. The online shop is important, but it’s not a core subdomain. The jewelry design is. (Location 610)
As a more intricate example, imagine a company that specializes in manual fraud detection. The company trains its analysts to go over questionable documents and flag potential fraud cases. You are building the software system the analysts are working with. Is it a core subdomain? No. The core subdomain is the work the analysts are doing. The system you are building has nothing to do with fraud analysis, it just displays the documents and tracks the analysts’ comments. (Location 617)
Generic subdomains are business activities that all companies are performing in the same way. Like core subdomains, generic subdomains are generally complex and hard to implement. However, generic subdomains do not provide any competitive edge for the company. There is no need for innovation or optimization here: battle-tested implementations are widely available, and all companies use them. (Location 633)
As the name suggests, supporting subdomains support the company’s business. However, contrary to core subdomains, supporting subdomains do not provide any competitive advantage. (Location 648)
The distinctive characteristic of supporting subdomains is the complexity of the solution’s business logic. Supporting subdomains are simple. Their business logic resembles mostly data entry screens and ETL (extract, transform, load) operations; that is, the so-called CRUD (create, read, update, and delete) interfaces. These activity areas do not provide any competitive advantage for the company, and therefore do not require high entry barriers. (Location 658)
Only core subdomains provide a competitive advantage to a company. Core subdomains are the company’s strategy for differentiating itself from its competitors. (Location 668)
Generic subdomains, by definition, cannot be a source for any competitive advantage. These are generic solutions—the same solutions used by the company and its competitors. (Location 676)
times it may be challenging to differentiate between core and supporting subdomains. Complexity is a useful guiding principle. Ask whether the subdomain in question can be turned into a side business. Would someone pay for it on its own? If so, this is a core subdomain. Similar (Location 712)
Another useful guiding principle for identifying software-related core subdomains is to evaluate the complexity of the business logic that you will have to model and implement in code. Does the business logic resemble CRUD interfaces for data entry, or do you have to implement complex algorithms or business processes orchestrated by complex business rules and invariants? In the former case, it’s a sign of a supporting subdomain, while the latter is a typical core subdomain. (Location 720)
solutions for core subdomains are emergent. Different implementations have to be tried out, refined, and optimized. Moreover, the work on core subdomains is never done. Companies continuously innovate and evolve core subdomains. (Location 735)
Core subdomains provide the company its ability to compete with other players in the industry. That’s a business-critical responsibility, but does it mean that supporting and generic subdomains are not important? Of course not. All subdomains are required for the company to work in its business domain. (Location 743)
Lack of competitive advantage makes it reasonable to avoid implementing supporting subdomains in-house. However, unlike generic subdomains, no ready-made solutions are available. So, a company has no choice but to implement supporting subdomains itself. That said, the simplicity of the business logic and infrequency of changes make it easy to cut corners. (Location 765)
Table 1-1. The differences between the three types of subdomains Subdomain type Competitive advantage Complexity Volatility Implementation Problem Core Yes High High In-house Interesting Generic No High Low Buy/adopt Solved Supporting No Low Low In-house/outsource Obvious Identifying Subdomain (Location 775)
But how do we actually identify the subdomains and their boundaries? The subdomains and their types are defined by the company’s business strategy: its business domains and how it differentiates itself to compete with other companies in the same field. In the vast majority of software projects, in one way or another the subdomains are “already there.” That doesn’t mean, however, that it is always easy and straightforward to identify their boundaries. (Location 784)
A good starting point is the company’s departments and other organizational units. For example, an online retail shop might include warehouse, customer service, picking, shipping, quality control, and channel management departments, among others. These, however, are relatively coarse-grained areas of activity. (Location 791)
Subdomains as coherent use cases From a technical perspective, subdomains resemble sets of interrelated, coherent use cases. Such sets of use cases usually involve the same actor, the business entities, and they all manipulate a closely related set of data. (Location 810)
We can use the definition of “subdomains as a set of coherent use cases” as a guiding principle for when to stop looking for finer-grained subdomains. These are the most precise boundaries of the subdomains. (Location 817)
Focus on the essentials Subdomains are a tool that alleviates the process of making software design decisions. All organizations likely have quite a few business functionalities that drive their competitive advantage but have nothing to do with software. The jewelry maker we discussed earlier in this chapter is but one example. When looking for subdomains, it’s important to identify business functions that are not related to software, acknowledge them as such, and focus on aspects of the business that are relevant to the software system you are working on. (Location 832)
Domain experts are subject matter experts who know all the intricacies of the business that we are going to model and implement in code. In other words, domain experts are knowledge authorities in the software’s business domain. (Location 910)
The domain experts are neither the analysts gathering the requirements nor the engineers designing the system. Domain experts represent the business. They are the people who identified the business problem in the first place and from whom all business knowledge originates. (Location 911)
As a rule of thumb, domain experts are either the people coming up with requirements or the software’s end users. The software is supposed to solve their problems. (Location 914)
The domain experts’ expertise can have different scopes. Some subject matter experts will have a detailed understanding of how the entire business domain operates, while others will specialize in particular subdomains. (Location 915)
For example, in an online advertising agency, the domain experts would be campaign managers, media buyers, analysts, and other business stakeholders. (Location 917)
Core subdomains The interesting problems. These are the activities the company is performing differently from its competitors and from which it gains its competitive advantage. (Location 921)
Generic subdomains The solved problems. These are the things all companies are doing in the same way. There is no room or need for innovation here; rather than creating in-house implementations, it’s more cost-effective to use existing solutions. (Location 923)
Supporting subdomains The problems with obvious solutions. These are the activities the company likely has to implement in-house, but that do not provide any competitive advantage. (Location 924)
ubiquitous language to drive software design decisions, the language must be clear and consistent. It should be free of ambiguity, implicit assumptions, and extraneous details. (Location 946)
Inconsistent Models (Location 953)
The closer the implementations of the conflicting models are, the easier it is to make a mistake. Second, the implementation of the model won’t be aligned with the ubiquitous language. No one would use the prefixes in conversations. People don’t need this extra information; they can rely on the conversation’s context. (Location 981)
divide the ubiquitous language into multiple smaller languages, then assign each one to the explicit context in which it can be applied: its bounded context. (Location 987)
Model Boundaries (Location 1000)
In other words, bounded contexts are the consistency boundaries of ubiquitous languages. A language’s terminology, principles, and business (Location 1009)
Bounded contexts allow us to complete the definition of a ubiquitous language. A ubiquitous language is not “ubiquitous” in the sense that it should be used and applied “ubiquitously” throughout the organization. A ubiquitous language is not universal. (Location 1011)
ubiquitous language is ubiquitous only in the boundaries of its bounded context. The language is focused on describing only the model that is encompassed by the bounded context. (Location 1013)
Boundaries can be wide, following the business domain’s inherent contexts, or narrow, further dividing the business domain into smaller problem domains. (Location 1026)
The reasons for extracting finer-grained bounded contexts out of a larger one include constituting new software engineering teams or addressing some of the system’s nonfunctional requirements; for example, when you need to separate the development lifecycles of some of the components originally residing in a single bounded context. Another common reason for extracting one functionality is the ability to scale it independently from the rest of the bounded context’s functionalities. (Location 1032)
Subdomains To comprehend a company’s business strategy, we have to analyze its business domain. According to domain-driven design methodology, the analysis phase involves identifying the different subdomains (core, supporting, and generic). That’s how the organization works and plans its competitive strategy. (Location 1055)
Bounded Contexts Bounded contexts, on the other hand, are designed. Choosing models’ boundaries is a strategic design decision. We decide how to divide the business domain into smaller, manageable problem domains. (Location 1060)
a single model could span the entire business domain. This strategy could work for a small system, as shown in Figure 3-5. Figure 3-5. Monolithic bounded context When conflicting models arise, we can follow the domain experts’ mental models and decompose the systems into bounded contexts, as shown in Figure 3-6. (Location 1063)
It’s crucial to remember that subdomains are discovered and bounded contexts are designed.1 The subdomains are defined by the business strategy. However, we can design the software solution and its bounded contexts to address the specific project’s context and constraints. (Location 1076)
Boundaries (Location 1087)
Physical Boundaries (Location 1098)
Ownership Boundaries (Location 1108)
In software projects, we can leverage model boundaries—bounded contexts—for the peaceful coexistence of teams. The division of work between teams is another strategic decision that can be made using the bounded context pattern. (Location 1112)
bounded context should be implemented, evolved, and maintained by one team only. No two teams can work on the same bounded context. This segregation eliminates implicit assumptions that teams might make about one another’s models. Instead, they have to define communication protocols for integrating their models and systems explicitly. (Location 1113)
relationship between teams and bounded contexts is one-directional: a bounded context should be owned by only one team. However, a single team can own multiple bounded contexts, as Figure 3-8 illustrates. (Location 1116)
A semantic domain is defined as an area of meaning and the words used to talk about it. For example, the words monitor, port, and processor have different meanings in the software and hardware engineering semantic domains. (Location 1135)
Chapter 4. Integrating Bounded Contexts
the components have to interact with one another to achieve the system’s overarching goals—so, too, do the implementations in bounded contexts. Although they can evolve independently, they have to integrate with one another. As a result, there will always be touchpoints between bounded contexts. These are called contracts. (Location 1225)
Cooperation patterns relate to bounded contexts implemented by teams with well-established communication. In the simplest case, these are bounded contexts implemented by a single team. This also applies to teams with dependent goals, where one team’s success depends on the success of the other, and vice versa. Again, the main criterion here is the quality of the teams’ communication and collaboration. (Location 1234)
the partnership model, the integration between bounded contexts is coordinated in an ad hoc manner. One team can notify a second team about a change in the API, and the second team will cooperate and adapt—no drama or conflicts (Location 1245)
The coordination of integration here is two-way. No one team dictates the language that is used for defining the contracts. The teams can work out the differences and choose the most appropriate solution. Also, both sides cooperate in solving any integration issues that might come up. Neither team is interested in blocking the other one. (Location 1253)
Well-established collaboration practices, high levels of commitment, and frequent synchronizations between teams are required for successful integration in this manner. (Location 1255)
This pattern might not be a good fit for geographically distributed teams since it may present synchronization and communication challenges. (Location 1257)
bounded contexts being model boundaries, there still can be cases when the same model of a subdomain, or a part of it, will be implemented in multiple bounded contexts. It’s crucial to stress that the shared model is designed according to the needs of all of the bounded contexts. Moreover, the shared model has to be consistent across all of the bounded contexts that are using it. (Location 1259)
Implementation (Location 1276)
If the organization uses the mono-repository approach, these can be the same source files referenced by multiple bounded contexts. (Location 1278)
If using a shared repository is not possible, the shared kernel can be extracted into a dedicated project and referenced in the bounded contexts as a linked library. Either way, each change to the shared kernel must trigger integration tests for all the affected bounded contexts. (Location 1279)
The overarching applicability criterion for the shared kernel pattern is the cost of duplication versus the cost of coordination. Since the pattern introduces a strong dependency between the participating bounded contexts, it should be applied only when the cost of duplication is higher than the cost of coordination—in (Location 1284)
Another common use case for applying the shared kernel pattern, albeit a temporary one, is the gradual modernization of a legacy system. In such a scenario, the shared codebase can be a pragmatic intermediate solution for gradually decomposing the system into bounded contexts. (Location 1298)
Finally, a shared kernel can be a good fit for integrating bounded contexts owned and implemented by the same team. In such a case, an ad hoc integration of the bounded contexts—a partnership—can “wash out” the contexts’ boundaries over time. A shared kernel can be used for explicitly defining (Location 1300)
Customer–Supplier (Location 1310)
Unlike in the cooperation case, both teams (upstream and downstream) can succeed independently. Consequently, in most cases we have an imbalance of power: either the upstream or the downstream team can dictate the integration contract. (Location 1321)
In some cases, the balance of power favors the upstream team, which has no real motivation to support its clients’ needs. Instead, it just provides the integration contract, defined according to its own model—take it or leave it. Such power imbalances can be caused by integration with service providers that are external to the organization or simply by organizational politics. If the downstream team can accept the upstream team’s model, the bounded contexts’ relationship is called conformist. The downstream conforms to the upstream bounded context’s model, as shown in (Location 1325)
The downstream team’s decision to give up some of its autonomy can be justified in multiple ways. For example, the contract exposed by the upstream team may be an industry-standard, well-established model, or it may just be good enough for the downstream team’s needs. (Location 1334)
As in the conformist pattern, the balance of power in this relationship is still skewed toward the upstream service. However, in this case, the downstream bounded context is not willing to conform. Instead, it can translate the upstream bounded context’s model into a model tailored to its own needs via an anticorruption layer, as shown in Figure 4-5. (Location 1337)
The anticorruption layer pattern addresses scenarios in which it is not desirable or worth the effort to conform to the supplier’s model, such as the following: (Location 1345)
When the downstream bounded context contains a core subdomain (Location 1346)
When the upstream model is inefficient or inconvenient for the consumer’s needs (Location 1348)
When the supplier’s contract changes often (Location 1349)
This pattern addresses cases in which the power is skewed toward the consumers. The supplier is interested in protecting its consumers and providing the best service possible. (Location 1354)
To protect the consumers from changes in its implementation model, the upstream supplier decouples the implementation model from the public interface. This decoupling allows the supplier to evolve its implementation and public models at different rates, (Location 1359)
The supplier’s public interface is not intended to conform to its ubiquitous language. Instead, it is intended to expose a protocol convenient for the consumers, expressed in an integration-oriented language. As such, the public protocol is called the published language. In a sense, the open-host service pattern is a reversal (Location 1362)
Decoupling the bounded context’s implementation and integration models gives the upstream bounded context the freedom to evolve its implementation without affecting the downstream contexts. Of course, that’s only possible if the modified implementation model can be translated into the published language the consumers are already using. Furthermore, (Location 1368)
The last collaboration option is not to collaborate at all. This pattern can arise for different reasons, in cases where the teams are unwilling or unable to collaborate. We’ll look at a few of them here. (Location 1378)
common reason for avoiding collaboration is communication difficulties driven by the organization’s size or internal politics. When teams have a hard time collaborating and agreeing, it may be more cost-effective to go their separate ways and duplicate functionality in multiple bounded contexts. (Location 1387)
The nature of the duplicated subdomain can also be a reason for teams to go their separate ways. When the subdomain in question is generic, and if the generic solution is easy to integrate, it may be more cost-effective to integrate it locally in each bounded context. An example is a logging framework; it would make little sense for one of the bounded contexts to expose it as a service. The (Location 1393)
Differences in the bounded contexts’ models can also be a reason to go with a separate ways collaboration. The models may be so different that a conformist relationship is impossible, and implementing an anticorruption layer would be more expensive than duplicating the functionality. In such a case, it is again more cost-effective for the teams to go their separate ways. (Location 1401)
Context Map (Location 1410)
context map is a visual representation of the system’s bounded contexts and the integrations between them. This visual notation gives valuable strategic insight on multiple levels: (Location 1414)
High-level design A context map provides an overview of the system’s components and the models they implement. Communication patterns A context map depicts the communication patterns among teams—for example, which teams are collaborating and which prefer “less intimate” integration patterns, such as the anticorruption layer and separate ways patterns. Organizational issues A context map can give insight into organizational issues. For example, what does it mean if a certain upstream team’s downstream consumers all resort to implementing an anticorruption layer, or if all implementations of the separate ways pattern are concentrated around the same team? (Location 1416)
even if bounded contexts are limited to a single subdomain, there still can be multiple integration patterns at play—for example, if the subdomains’ modules require different integration strategies. (Location 1435)
Part II. Tactical Design
Chapter 5. Implementing Simple Business Logic (Location 1477)
Transaction Script Organizes business logic by procedures where each procedure handles a single request from the presentation. —Martin Fowler1 (Location 1486)
A system’s public interface can be seen as a collection of business transactions that consumers can execute, as shown in Figure 5-1. These transactions can retrieve information managed by the system, modify it, or both. The pattern organizes the system’s business logic based on procedures, where each procedure implements an operation that is executed by the system’s consumer via its public interface. In effect, the system’s public operations are used as encapsulation boundaries. (Location 1491)
Each procedure is implemented as a simple, straightforward procedural script. It can use a thin abstraction layer for integrating with storage mechanisms, but it is also free to access the databases directly. The only requirement procedures have to fulfill is transactional behavior. Each operation should either succeed or fail but can never result in an invalid state. Even if execution of a transaction script fails at the most inconvenient moment, the system should remain consistent—either by rolling back any changes it has made up until the failure or by executing compensating actions. The transactional behavior is reflected in the pattern’s name: transaction script. (Location 1497)
The transaction script pattern is well adapted to the most straightforward problem domains in which the business logic resembles simple procedural operations. For example, in extract-transform-load (ETL) operations, each operation extracts data from a source, applies transformation logic to convert it into another form, and loads the result into the destination store. (Location 1622)
The transaction script pattern naturally fits supporting subdomains where, by definition, the business logic is simple. It can also be used as an adapter for integration with external systems—for example, generic subdomains, or as a part of an anticorruption layer (Location 1631)
The main advantage of the transaction script pattern is its simplicity. It introduces minimal abstractions and minimizes the overhead both in runtime performance and in understanding the business logic. That said, this simplicity is also the pattern’s disadvantage. The more complex the business logic gets, the more it’s prone to duplicate business logic across transactions, and consequently, to result in inconsistent behavior—when the duplicated code goes out of sync. As a result, transaction script should never be used for core subdomains, as this pattern won’t cope with the high complexity of a core subdomain’s business logic. (Location 1633)
An object that wraps a row in a database table or view, encapsulates the database access, and adds domain logic on that data. —Martin Fowler2 Like the transaction script pattern, active record supports cases where the business logic is simple. Here, however, the business logic may operate on more complex data structures. (Location 1645)
Implementation Consequently, this pattern uses dedicated objects, known as active records, to represent complicated data structures. Apart from the data structure, these objects also implement data access methods for creating, reading, updating, and deleting records—the so-called CRUD operations. As a result, the active record objects are coupled to an object-relational mapping (ORM) or some other data access framework. The pattern’s name is derived from the fact that each data (Location 1654)
The pattern’s goal is to encapsulate the complexity of mapping the in-memory object to the database’s schema. In addition to being responsible for persistence, the active record objects can contain business logic; for example, validating new values assigned to the fields, or even implementing business-related procedures that manipulate an object’s data. That said, the distinctive feature of an active record object is the separation of data structures and behavior (business logic). Usually, an active record’s fields have public getters and setters that allow external procedures to modify its (Location 1677)
Because an active record is essentially a transaction script that optimizes access to databases, this pattern can only support relatively simple business logic, such as CRUD operations, which, at most, validate the user’s input. (Location 1682)
Accordingly, as in the case of the transaction script pattern, the active record pattern lends itself to supporting subdomains, integration of external solutions for generic subdomains, or model transformation tasks. The difference between the patterns is that active record addresses the complexity of mapping complicated data structures to a database’s schema. (Location 1685)
The active record pattern is also known as an anemic domain model antipattern; in other words, an improperly designed domain model. (Location 1688)
Domain Model
Here, instead of CRUD interfaces, we deal with complicated state transitions, business rules, and invariants: rules that have to be protected at all times. (Location 1767)
A domain model is an object model of the domain that incorporates both behavior and data.1 DDD’s tactical patterns—aggregates, value objects, domain events, and domain services—are the building blocks of such an object model. (Location 1780)
All of these patterns share a common theme: they put the business logic first. Let’s see how the domain model addresses different design concerns. (Location 1785)
Complexity The domain’s business logic is already inherently complex, so the objects used for modeling it should not introduce any additional accidental complexities. The model should be devoid of any infrastructural or technological concerns, such as implementing calls to databases or other external components of the system. This restriction requires the model’s objects to be plain old objects, objects implementing business logic without relying on or directly incorporating any infrastructural components or frameworks. (Location 1787)
Building Blocks (Location 1798)
Value object A value object is an object that can be identified by the composition of its values. For example, consider a color object: class Color
{
int _red;
int _green;
int _blue;
} The composition of the values of the three fields red, green, and blue defines a color. Changing the value of one of the fields will result in a new color. No two colors can have the same values. Also, two instances of the same color must have the same values. (Location 1799)
In the preceding implementation of the Person class, most of the values are of type String and they are assigned based on convention. For example, the input to the landlinePhone should be a valid landline phone number, and the countryCode should be a valid, two-letter, uppercased country code. Of course, the system cannot trust the user to always supply correct values, and as a result, the class has to validate all input fields. This approach presents multiple design risks. First, the validation logic tends to be duplicated. Second, it’s hard to enforce calling the validation logic before the values are used. It will become even more challenging in the future, when the codebase will be evolved by other engineers. Compare the following alternative design of the same object, this time leveraging value objects: class Person {
private PersonId _id;
private Name _name;
private PhoneNumber _landline;
private PhoneNumber _mobile;
private EmailAddress _email;
private Height _height;
private CountryCode _country;
public Person(…) { … }
}
static void Main(string[] args)
{
var dave = new Person(
id: new PersonId(30217),
name: new Name(“Dave”, “Ancelovici”),
landline: PhoneNumber.Parse(“023745001”),
mobile: PhoneNumber.Parse(“0873712503”),
email: Email.Parse(“dave@learning-ddd.com”),
height: Height.FromMetric(180),
country: CountryCode.Parse(“BG”));
} First, notice the increased clarity. Take, for example, the country variable. There is no need to elaborately call it “countryCode” to communicate the intent of it holding a country code and not, for example, a full country name. The value object makes the intent clear, even with shorter variable names. (Location 1835)
Second, there is no need to validate the values before the assignment, as the validation logic resides in the value objects themselves. However, a value object’s behavior is not limited to mere validation. Value objects shine brightest when they centralize the business logic that manipulates the values. The cohesive logic is implemented in one place and is easy to test. Most importantly, value objects express the business domain’s concepts: they make the code speak the ubiquitous language. Let’s (Location 1863)
Implementation Since a change to any of the fields of a value object results in a different value, value objects are implemented as immutable objects. A change to one of the value object’s fields conceptually creates a different value—a different instance of a value object. Therefore, when an executed action results in a new value, as in the following case, which uses the MixWith method, it doesn’t modify the original instance but instantiates and returns a new one: (Location 1899)
When to use value objects The simple answer is, whenever you can. Not only do value objects make the code more expressive and encapsulate business logic that tends to spread apart, but the pattern makes the code safer. Since value objects are immutable, the value objects’ behavior is free of side effects and is thread safe. (Location 1952)
An entity is the opposite of a value object. It requires an explicit identification field to distinguish between the different instances of the entity. A trivial example of an entity is a person. (Location 1964)
The central requirement for the identification field is that it should be unique for each instance of the entity: for each person, in our case (Figure 6-2). Furthermore, except for very rare exceptions, the value of an entity’s identification field should remain immutable throughout the entity’s lifecycle. This brings us to the second conceptual difference between value objects and entities. (Location 1988)
- Note: Add a graph
Contrary to value objects, entities are not immutable and are expected to change. (Location 1993)
An aggregate is an entity: it requires an explicit identification field and its state is expected to change during an instance’s lifecycle. However, it is much more than just an entity. The goal of the pattern is to protect the consistency of its data. Since an aggregate’s data is mutable, there are implications and challenges that the pattern has to address to keep its state consistent at all times. (Location 2000)
To enforce consistency of the data, the aggregate pattern draws a clear boundary between the aggregate and its outer scope: the aggregate is a consistency enforcement boundary. The aggregate’s logic has to validate all incoming modifications and ensure that the changes do not contradict its business rules. (Location 2015)
From an implementation perspective, the consistency is enforced by allowing only the aggregate’s business logic to modify its state. All processes or objects external to the aggregate are only allowed to read the aggregate’s state. Its state can only be mutated by executing corresponding methods of the aggregate’s public interface. (Location 2017)
An aggregate’s public interface is responsible for validating the input and enforcing all of the relevant business rules and invariants. This strict boundary also ensures that all business logic related to the aggregate is implemented in one place: the aggregate itself. (Location 2041)
This makes the application layer6 that orchestrates operations on aggregates rather simple:7 all it has to do is load the aggregate’s current state, execute the required action, persist the modified state, and return the operation’s result to the caller: (Location 2043)
It’s vital to protect the consistency of an aggregate’s state.8 If multiple processes are concurrently updating the same aggregate, we have to prevent the latter transaction from blindly overwriting the changes committed by the first one. In such a case, the second process has to be notified that the state on which it had based its decisions is out of date, and it has to retry the operation. (Location 2060)
Transaction boundary Since an aggregate’s state can only be modified by its own business logic, the aggregate also acts as a transactional boundary. All changes to the aggregate’s state should be committed transactionally as one atomic operation. If an aggregate’s state is modified, either all the changes are committed or none of them is. (Location 2079)
The one aggregate instance per transaction forces us to carefully design an aggregate’s boundaries, ensuring that the design addresses the business domain’s invariants and rules. The need to commit changes in multiple aggregates signals a wrong transaction boundary, and hence, wrong aggregate boundaries. (Location 2085)
Hierarchy of entities (Location 2089)
hierarchy contains both entities and value objects, and all of them belong to the same aggregate if they are bound by the domain’s business logic. That’s why the pattern is named “aggregate”: it aggregates business entities and value objects that belong to the same transaction boundary. (Location 2098)
The aggregate ensures that all the conditions are checked against strongly consistent data, and it won’t change after the checks are completed by ensuring that all changes to the aggregate’s data are performed as one atomic transaction. (Location 2125)
Only the information that is required by the aggregate’s business logic to be strongly consistent should be a part of the aggregate. All information that can be eventually consistent should reside outside of the aggregate’s boundary; for example, as a part of another aggregate, (Location 2132)
The rule of thumb is to keep the aggregates as small as possible and include only objects that are required to be in a strongly consistent state by the aggregate’s business logic: (Location 2136)
In the preceding example, the Ticket aggregate references a collection of messages, which belong to the aggregate’s boundary. On the other hand, the customer, the collection of products that are relevant to the ticket, and the assigned agent do not belong to the aggregate and therefore are referenced by its (Location 2143)
The reasoning behind referencing external aggregates by ID is to reify that these objects do not belong to the aggregate’s boundary, and to ensure that each aggregate has its own transactional boundary. (Location 2145)
decide whether an entity belongs to an aggregate or not, examine whether the aggregate contains business logic that can lead to an invalid system state if it will work on eventually consistent data. Let’s go back to the previous example of reassigning the ticket if the current agent didn’t read the new messages within 50% of the response time limit. What if the information about read/unread messages would be eventually consistent? In other words, it would be reasonable to receive reading acknowledgment after a certain delay. (Location 2147)
The aggregate root (Location 2152)
Since an aggregate represents a hierarchy of entities, only one of them should be designated as the aggregate’s public interface—the aggregate root, (Location 2156)
A domain event is a message describing a significant event that has occurred in the business domain. For example: Ticket assigned Ticket escalated Message received (Location 2173)
Since domain events describe something that has already happened, their names should be formulated in the past tense. (Location 2177)
The goal of a domain event is to describe what has happened in the business domain and provide all the necessary data related to the event. For example, the following domain event communicates that the specific ticket was escalated, at what time, and for what reason: (Location 2178)
Domain events are part of an aggregate’s public interface. An aggregate publishes its domain events. Other processes, aggregates, or even external systems can subscribe to and execute their own logic in response to the domain events, (Location 2186)
Last but not least, aggregates should reflect the ubiquitous language. The terminology that is used for the aggregate’s name, its data members, its actions, and its domain events all should be formulated in the bounded context’s ubiquitous language. (Location 2207)
Sooner or later, you may encounter business logic that either doesn’t belong to any aggregate or value object, or that seems to be relevant to multiple aggregates. In such cases, domain-driven design proposes to implement the logic as a domain service. (Location 2218)
A domain service is a stateless object that implements the business logic. In the vast majority of cases, such logic orchestrates calls to various components of the system to perform some calculation or analysis. (Location 2223)
The response time frame calculation logic requires information from multiple sources: the ticket, the assigned agent’s department, and the work schedule. That makes it an ideal candidate to be implemented as a domain service: (Location 2228)
Domain services make it easy to coordinate the work of multiple aggregates. However, it is important to always keep in mind the aggregate pattern’s limitation of modifying only one instance of an aggregate in one database transaction. (Location 2246)
Instead, domain services lend themselves to implementing calculation logic that requires reading the data of multiple aggregates. (Location 2250)
It is also important to point out that domain services have nothing to do with microservices, service-oriented architecture, or almost any other use of the word service in software engineering. It is just a stateless object used to host business logic. (Location 2251)
system’s degrees of freedom are the data points needed to describe its state. (Location 2263)
Let’s analyze both classes from the degrees-of-freedom perspective. How many data elements do you need to describe the state of ClassA? The answer is five: its five variables. Hence, ClassA has five degrees of freedom. (Location 2291)
How many data elements do you need to describe the state of ClassB? If you look at the assignment logic for properties A and D, you will notice that the values of B, C, and E are functions of the values of A and D. If you know what A and D are, then you can deduce the values of the rest of the variables. Therefore, ClassB has only two degrees of freedom. (Location 2292)
Going back to the original question, which class is more difficult in terms of controlling and predicting its behavior? The answer is the one with more degrees of freedom, or ClassA. The invariants introduced in ClassB reduce its complexity. That’s what both aggregate and value object patterns do: (Location 2296)
All the business logic related to the state of a value object is located in its boundaries. The same is true for aggregates. An aggregate can only be modified by its own methods. Its business logic encapsulates and protects business invariants, thus reducing the degrees of freedom. (Location 2305)
Since the domain model pattern is applied only for subdomains with complex business logic, it’s safe to assume that these are core subdomains—the heart of the software. (Location 2307)
New highlights added 03-09-2024 at 7:30 AM
Event Sourcing (Location 2375)
The event sourcing pattern introduces the dimension of time into the data model. Instead of the schema reflecting the aggregates’ current state, an event sourcing–based system persists events documenting every change in an aggregate’s lifecycle. (Location 2424)
Pay attention to the Version field that is incremented after applying each event. Its value represents the total number of modifications made to the business entity. (Location 2502)
Applying this projection logic to Casey Davis’s events from the earlier example will result in the following state: LeadId: 12
FirstNames: [‘Casey’]
LastNames: [‘David’, ‘Davis’]
PhoneNumbers: [‘555-2951’, ‘555-8101’]
Version: 6 (Location 2562)
Source of Truth (Location 2606)
The database that stores the system’s events is the only strongly consistent storage: the system’s source of truth. The accepted name for the database that is used for persisting events is event store. Event Store (Location 2611)
The event store should not allow modifying or deleting the events2 since it’s append-only storage. To support implementation of the event sourcing pattern, at a minimum the event store has to support the following functionality: fetch all events belonging to a specific business entity and append the events. (Location 2614)
If it’s stale, that is, new events were added after the expected version, the event store should raise a concurrency exception. (Location 2625)
essence, the event sourcing pattern is nothing new. The financial industry uses events to represent changes in a ledger. A ledger is an append-only log that documents transactions. A current state (e.g., account balance) can always be deduced by “projecting” the ledger’s records. (Location 2627)
Each operation on an event-sourced aggregate follows this script: Load the aggregate’s domain events. Reconstitute a state representation—project the events into a state representation that can be used to make business decisions. Execute the aggregate’s command to execute the business logic, and consequently, produce new domain events. Commit the new domain events to the event store. (Location 2639)
Advantages (Location 2723)
Just as the domain events can be used to reconstitute an aggregate’s current state, they can also be used to restore all past states of the aggregate. (Location 2728)
Deep insight (Location 2739)
Event sourcing provides deep insight into the system’s state and behavior. As you learned earlier in this chapter, event sourcing provides the flexible model that allows for transforming the events into different state representations—you can always add new projections that will leverage the existing events’ data to provide additional insights. (Location 2742)
log The persisted domain events represent a strongly consistent audit log of everything that has happened to the aggregates’ states. Laws oblige some business domains to implement such audit logs, and event sourcing provides this out of the box. (Location 2745)
Advanced optimistic concurrency management The classic optimistic concurrency model raises an exception when the read data becomes stale—overwritten by another process—while it is being written. (Location 2749)
Disadvantages (Location 2754)
Learning curve The obvious disadvantage of the pattern is its sharp difference from the traditional techniques of managing data. Successful implementation of the pattern demands training of the team and time to get used to the new way of thinking. (Location 2760)
Evolving the model Evolving an event-sourced model can be challenging. The strict definition of event sourcing says that events are immutable. (Location 2762)
Architectural complexity Implementation of event sources introduces numerous architectural “moving parts,” making the overall design more complicated. (Location 2769)
snapshot. This pattern, shown in Figure 7-2, implements the following steps: A process continuously iterates new events in the event store, generates corresponding projections, and stores them in a cache. An in-memory projection is needed to execute an action on the aggregate. In this case: The process fetches the current state projection from the cache. The process fetches the events that came after the snapshot version from the event store. The additional events are applied in-memory to the snapshot. (Location 2789)
snapshot pattern is an optimization that has to be justified. If the aggregates in your system won’t persist 10,000+ events, implementing the snapshot pattern is just an accidental complexity. (Location 2795)
This need can be addressed with the forgettable payload pattern: all sensitive information is included in the events in encrypted form. The encryption key is stored in an external key–value store: the key storage, where the key is a specific aggregate’s ID and the value is the encryption key. When the sensitive data has to be deleted, the encryption key is deleted from the key storage. As a result, the sensitive information contained in the events is no longer accessible. (Location 2813)
Architectural Patternstodo
Layered Architecture (Location 2897)
It organizes the codebase into horizontal layers, with each layer addressing one of the following technical concerns: interaction with the consumers, implementing business logic, and persisting the data. You can see this represented in Figure 8-1. (Location 2899)
Presentation Layer (Location 2904)
In the pattern’s original form, this layer denotes a graphical interface, such as a web interface or a desktop application. (Location 2908)
In modern systems, however, the presentation layer has a broader scope: that is, all means for triggering the program’s behavior, both synchronous and asynchronous. For example: Graphical user interface (GUI) Command-line interface (CLI) API for programmatic integration with other systems Subscription to events in a message broker Message topics for publishing outgoing events All (Location 2909)
Strictly speaking, the presentation layer is the program’s public interface. (Location 2913)
this layer is responsible for implementing and encapsulating the program’s business logic. This is the place where business decisions are implemented. (Location 2915)
Data Access Layer (Location 2924)
provides access to persistence mechanisms. In the pattern’s original form, this referred to the system’s database. (Location 2925)
top-down communication model: each layer can hold a dependency only on the layer directly beneath it, as shown in Figure 8-5. This enforces decoupling of implementation concerns and reduces the knowledge shared between the layers. (Location 2938)
When to Use Layered Architecture (Location 3045)
this architectural pattern a good fit for a system with its business logic implemented using the transaction script or active record pattern. (Location 3051)
However, the pattern makes it challenging to implement a domain model. In a domain model, the business entities (aggregates and value objects) should have no (Location 3052)
Ports & Adapters (Location 3076)
Dependency Inversion Principle (Location 3096)
high-level modules, which implement the business logic, should not depend on low-level modules. (Location 3105)
New highlights added 11-09-2024 at 8:02 AM
Instead of referencing and calling the infrastructural components directly, the business logic layer defines “ports” that have to be implemented by the infrastructure layer. The infrastructure layer implements “adapters”: concrete implementations of the ports’ interfaces for working with different technologies (see Figure 8-11). (Location 3130)
Variants (Location 3143)
The ports & adapters architecture is also known as hexagonal architecture, onion architecture, and clean architecture. (Location 3144)
in the case of the layered architecture, the terminology may differ: Application layer = service layer = use case layer Business logic layer = domain layer = core layer (Location 3147)
When to Use Ports & Adapters (Location 3151)
a perfect fit for business logic implemented with the domain model pattern. (Location 3154)
CQRS
-query responsibility segregation (CQRS) pattern is based on the same organizational principles for business logic and infrastructural concerns as ports & adapters. It differs, however, in the way the system’s data is managed. (Location 3155)
This pattern enables representation of the system’s data in multiple persistent models. (Location 3160)
Originally, CQRS was defined to address the limited querying possibilities of an event-sourced model: it is only possible to query events of one aggregate instance at a time. The CQRS pattern provides the possibility of materializing projected models into physical databases that can be used for flexible querying options. (Location 3177)
Implementation (Location 3182)
Command execution model (Location 3186)
This model is used to implement the business logic, validate rules, and enforce invariants. (Location 3190)
The command execution model is also the only model representing strongly consistent data—the system’s source of truth. (Location 3191)
It should be possible to read the strongly consistent state of a business entity and have optimistic concurrency support when updating (Location 3192)
Read models (projections) (Location 3193)
read model is a precached projection. It can reside in a durable database, flat file, or in-memory cache. (Location 3198)
Projecting Read Models (Location 3202)
The projection of read models is similar to the notion of a materialized view in relational databases: whenever source tables are updated, the changes have to be reflected in the precached views. (Location 3208)
projections fetch changes to the OLTP data through the catch-up subscription model: (Location 3211)
The projection engine uses the updated data to regenerate/update the system’s read models. (Location 3215)
The projection engine stores the checkpoint of the last processed record. This value will be used during the next iteration for getting records added or modified after the last processed record. (Location 3216)
the catch-up subscription to work, the command execution model has to checkpoint all the appended or updated database records. The storage mechanism should also support the querying of records based on the checkpoint. (Location 3221)
It’s important to ensure that the checkpoint-based query returns consistent results. If the last returned record has a checkpoint value of 10, on the next execution no new requests should have values lower than 10. (Location 3226)
Asynchronous projections (Location 3232)
Challenges (Location 3239)
it is more prone to the challenges of distributed computing. If the messages are processed out of order or duplicated, inconsistent data will be projected into the read models. (Location 3243)
it’s advisable to always implement synchronous projection and, optionally, an additional asynchronous projection on top (Location 3245)
Model Segregation (Location 3247)
In the CQRS architecture, the responsibilities of the system’s models are segregated according to their type. A command can only operate on the strongly consistent command execution model. A query cannot directly modify any of the system’s persisted state—neither the read models nor the command execution model. (Location 3248)
A command should always let the caller know whether it has succeeded or failed. If it has failed, why did it fail? Was there a validation or technical issue? The caller has to know how to fix the command. Therefore, a command can—and in many cases should—return data; (Location 3254)
When to Use CQRS (Location 3261)
From an operational perspective, the pattern supports domain-driven design’s core value of working with the most effective models for the task at hand, (Location 3264)
CQRS allows for leveraging the strength of the different kinds of databases; (Location 3266)
CQRS naturally lends itself to event-sourced domain models. (Location 3268)
These are not necessarily high-level architecture patterns for a whole bounded context either. (Location 3276)
Even subdomains of the same type may require different business logic and architectural patterns (that’s the topic of Chapter 10). Enforcing a single, bounded, contextwide architecture will inadvertently lead to accidental complexity. (Location 3278)